[DL101] Chương 8: Các mô hình Transformer cho Thị giác và Đa phương thức
Vision Transformers (ViT) và các mô hình đa phương thức (Multimodal)
Bài viết có tham khảo, sử dụng và sửa đổi tài nguyên từ kho lưu trữ handson-mlp, tuân thủ giấy phép Apache‑2.0. Chúng tôi chân thành cảm ơn tác giả Aurélien Géron (@aureliengeron) vì sự chia sẻ kiến thức tuyệt vời và những đóng góp quý giá cho cộng đồng.
Ở chương này, chúng ta sẽ khám phá Sự giao thoa giữa Thị giác máy tính (Computer Vision - CV) và Xử lý ngôn ngữ tự nhiên (NLP) thông qua kiến trúc Transformer.
Trước khi có Transformer, CNN là “ông vua” không thể tranh cãi của CV. Tuy nhiên, sự ra đời của Vision Transformer (ViT) đã chứng minh rằng kiến trúc dựa trên Attention có thể xử lý hình ảnh hiệu quả không kém, thậm chí vượt trội trong nhiều tác vụ. Hơn thế nữa, nó mở ra cánh cửa cho các mô hình đa phương thức (Multimodal Models) như CLIP hay BLIP-2, nơi hình ảnh và văn bản có thể được hiểu và xử lý đồng thời trong cùng một không gian vector.
Trong chương này, chúng ta sẽ:
- Xây dựng ViT từ đầu: Hiểu sâu về cách hình ảnh được “token hóa” thành các mảnh (patches).
- Sử dụng Pre-trained Models: Tận dụng sức mạnh của các mô hình khổng lồ như ViT-Base, DeiT, DINO, CLIP và BLIP-2.
- Thực hành các ứng dụng tiên tiến: Phân loại ảnh, phân vùng không giám sát, tìm kiếm hình ảnh bằng văn bản (Zero-shot classification), và hỏi đáp trên hình ảnh (Visual Q&A).
Bạn có thể chạy trực tiếp các đoạn mã code tại: Google Colab.
Cài đặt và Chuẩn bị môi trường
Để đảm bảo tính tái lập (reproducibility) trong nghiên cứu, việc thiết lập môi trường là bước đầu tiên và quan trọng nhất.
Kiểm tra phiên bản Python:
import sys
# Đảm bảo Python phiên bản >= 3.10
assert sys.version_info >= (3, 10)Xác định môi trường thực thi:
IS_COLAB = "google.colab" in sys.modules
IS_KAGGLE = "kaggle_secrets" in sys.modulesCài đặt thư viện TorchMetrics:
if IS_COLAB:
%pip install -q torchmetricsoutput:
[?25l [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [32m0.0/983.2 kB [0m [31m? [0m eta [36m-:--:-- [0m
[2K [91m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [90m╺ [0m [90m━━━━━━━━ [0m [32m768.0/983.2 kB [0m [31m23.7 MB/s [0m eta [36m0:00:01 [0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [32m983.2/983.2 kB [0m [31m15.8 MB/s [0m eta [36m0:00:00 [0m
[?25hKiểm tra phiên bản PyTorch (yêu cầu tối thiểu 2.6.0 để hỗ trợ các kiến trúc Transformer mới):
from packaging.version import Version
import torch
assert Version(torch.__version__) >= Version("2.6.0")Cấu hình thiết bị phần cứng (Hardware Accelerator). Transformer rất tốn tài nguyên tính toán ma trận, nên GPU là bắt buộc để huấn luyện hiệu quả.
if torch.cuda.is_available():
device = "cuda"
elif torch.backends.mps.is_available():
device = "mps"
else:
device = "cpu"
deviceoutput:
'cuda'Cảnh báo nếu không có GPU:
if device == "cpu":
print("Neural nets can be very slow without a hardware accelerator.")
if IS_COLAB:
print("Go to Runtime > Change runtime and select a GPU hardware "
"accelerator.")
if IS_KAGGLE:
print("Go to Settings > Accelerator and select GPU.")Cấu hình hiển thị biểu đồ:
import matplotlib.pyplot as plt
plt.rc('font', size=14)
plt.rc('axes', labelsize=14, titlesize=14)
plt.rc('legend', fontsize=14)
plt.rc('xtick', labelsize=10)
plt.rc('ytick', labelsize=10)1. Vision Transformers (ViT)
Vision Transformer (ViT) áp dụng kiến trúc Transformer tiêu chuẩn trực tiếp lên hình ảnh. Thay vì pixel, ViT xử lý các “mảnh ảnh” (patches).
1.1. Xây dựng ViT từ đầu (ViT From Scratch)
Cơ sở lý thuyết
ViT chia ảnh thành mảnh kích thước . Mỗi mảnh được làm phẳng thành vector chiều, sau đó chiếu tuyến tính vào không gian ẩn chiều.
Triển khai Code
Lớp PatchEmbedding sử dụng Conv2d để thực hiện chia mảnh và chiếu tuyến tính đồng thời (với kernel_size = stride = patch_size).
import torch
import torch.nn as nn
class PatchEmbedding(nn.Module):
def __init__(self, in_channels, embed_dim, patch_size=16):
super().__init__()
# Sử dụng Conv2d để vừa chia patch vừa chiếu tuyến tính (projection)
# Kernel size = Stride = patch_size giúp chia ảnh thành các ô không chồng lấn
self.conv2d = nn.Conv2d(in_channels, embed_dim,
kernel_size=patch_size, stride=patch_size)
def forward(self, X):
# X có shape: [Batch, Channels, Height, Width]
X = self.conv2d(X) # shape đầu ra: [Batch, Embed_Dim, H/P, W/P]
# Làm phẳng các chiều không gian thành một chuỗi
X = X.flatten(start_dim=2) # shape: [Batch, Embed_Dim, N_patches]
# Chuyển vị để có shape phù hợp với Transformer: [Batch, Sequence_Length, Embedding_Dim]
return X.transpose(1, 2) # shape: [Batch, N_patches, Embed_Dim]Mô hình ViT hoàn chỉnh bao gồm Patch Embedding, CLS Token, Positional Embedding và Transformer Encoder.
class ViT(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_channels=3,
num_classes=1000, embed_dim=768, depth=12, num_heads=12,
ff_dim=3072, dropout=0.1):
super().__init__()
# Lớp nhúng patch
self.patch_embed = PatchEmbedding(in_channels, embed_dim, patch_size)
# Khởi tạo CLS token (token dùng để phân loại)
# Đây là tham số có thể học (learnable parameter)
cls_init = torch.randn(1, 1, embed_dim) * 0.02
self.cls_token = nn.Parameter(cls_init) # shape [1, 1, E]
# Tính số lượng patches (ký hiệu là L hoặc N)
num_patches = (img_size // patch_size) ** 2
# Khởi tạo Positional Embedding (vị trí)
# +1 là dành cho vị trí của CLS token
pos_init = torch.randn(1, num_patches + 1, embed_dim) * 0.02
self.pos_embed = nn.Parameter(pos_init) # shape [1, 1 + L, E]
self.dropout = nn.Dropout(p=dropout)
# Khởi tạo một lớp Encoder tiêu chuẩn của Transformer
encoder_layer = nn.TransformerEncoderLayer(
d_model=embed_dim, nhead=num_heads, dim_feedforward=ff_dim,
dropout=dropout, activation="gelu", batch_first=True)
self.encoder = nn.TransformerEncoder(encoder_layer, num_layers=depth)
self.layer_norm = nn.LayerNorm(embed_dim)
self.output = nn.Linear(embed_dim, num_classes)
def forward(self, X):
# Bước 1: Patch Embedding
Z = self.patch_embed(X) # shape [B, L, E]
# Bước 2: Thêm CLS token vào đầu chuỗi
# Mở rộng CLS token cho kích thước batch
cls_expd = self.cls_token.expand(Z.shape[0], -1, -1) # shape [B, 1, E]
Z = torch.cat((cls_expd, Z), dim=1) # shape [B, 1 + L, E]
# Bước 3: Cộng Positional Embedding
Z = Z + self.pos_embed
Z = self.dropout(Z)
# Bước 4: Đi qua Transformer Encoder
Z = self.encoder(Z) # shape [B, 1 + L, E]
# Bước 5: Lấy vector tại vị trí đầu tiên (tương ứng với CLS token)
Z = self.layer_norm(Z[:, 0]) # shape [B, E]
# Bước 6: Phân loại
logits = self.output(Z) # shape [B, Num_Classes]
return logitsKiểm tra kích thước đầu ra:
# Khởi tạo mô hình
vit_model = ViT(
img_size=224, patch_size=16, in_channels=3, num_classes=1000, embed_dim=768,
depth=12, num_heads=12, ff_dim=3072, dropout=0.1)
# Tạo dữ liệu giả lập (batch size = 4)
batch = torch.randn(4, 3, 224, 224)
logits = vit_model(batch) # shape [4, 1000]logits.shapeoutput:
torch.Size([4, 1000])1.2. Tinh chỉnh (Fine-Tuning) mô hình ViT đã được huấn luyện trước
Sử dụng bộ dữ liệu Oxford-IIIT Pet và thư viện transformers.
from datasets import load_dataset
# Tải bộ dữ liệu Oxford Pets
pets = load_dataset("timm/oxford-iiit-pet")output:
...
Generating test split: 0%| | 0/3669 [00:00<?, ? examples/s]Hiển thị ảnh mẫu:
num_rows, num_cols = 2, 5
plt.figure(figsize=(num_cols * 2.5, num_rows * 2))
class_names = pets["train"].features["label"].names
for i in range(num_rows * num_cols):
plt.subplot(num_rows, num_cols, i + 1)
example = pets["train"][i]
plt.imshow(example["image"])
plt.title(class_names[example["label"]])
plt.axis("off")
Tải mô hình ViT pre-trained từ Hugging Face Hub:
from transformers import ViTForImageClassification, AutoImageProcessor
model_id = "google/vit-base-patch16-224-in21k"
# Tải mô hình với số nhãn đầu ra là 37 (số loại thú cưng trong tập dữ liệu)
vit_model = ViTForImageClassification.from_pretrained(model_id, num_labels=37)
vit_processor = AutoImageProcessor.from_pretrained(model_id, use_fast=True)output:
config.json: 0%| | 0.00/502 [00:00<?, ?B/s]
model.safetensors: 0%| | 0.00/346M [00:00<?, ?B/s]
...
preprocessor_config.json: 0%| | 0.00/160 [00:00<?, ?B/s]Kiểm tra vit_processor:
vit_processoroutput:
ViTImageProcessorFast {
...
"size": {
"height": 224,
"width": 224
}
}Thử nghiệm tiền xử lý ảnh:
num_rows, num_cols = 2, 5
plt.figure(figsize=(num_cols * 2.5, num_rows * 2))
class_names = pets["train"].features["label"].names
for i in range(num_rows * num_cols):
plt.subplot(num_rows, num_cols, i + 1)
example = pets["train"][i]
# Tiền xử lý ảnh
preprocessed = vit_processor(example["image"])["pixel_values"][0]
# Chuyển đổi tensor về dạng hiển thị được (un-normalize để vẽ)
plt.imshow((preprocessed.permute(1, 2, 0) + 1.) / 2.)
plt.title(class_names[example["label"]])
plt.axis("off")
Chuẩn bị hàm collate_fn và hàm tính độ chính xác compute_accuracy:
def vit_collate_fn(batch):
images = [example["image"] for example in batch]
labels = [example["label"] for example in batch]
# Xử lý ảnh và trả về pytorch tensors
inputs = vit_processor(images, return_tensors="pt", do_convert_rgb=True)
inputs["labels"] = torch.tensor(labels)
return inputs# Code bổ sung - hàm tính độ chính xác
def compute_accuracy(logits_and_labels):
logits, labels = logits_and_labels
preds = torch.tensor(logits).argmax(dim=1)
labels = torch.tensor(labels)
accuracy = (preds == labels).float().mean()
return {"accuracy": accuracy.item()}Huấn luyện với Trainer:
from transformers import Trainer, TrainingArguments
args = TrainingArguments("my_pets_vit", per_device_train_batch_size=16,
eval_strategy="epoch", num_train_epochs=3,
remove_unused_columns=False,
report_to="none") # Tắt báo cáo lên W&B hoặc TensorBoard để gọn gàng
trainer = Trainer(model=vit_model, args=args, data_collator=vit_collate_fn,
train_dataset=pets["train"], eval_dataset=pets["test"],
compute_metrics=compute_accuracy) # Thêm hàm đánh giá
train_output = trainer.train()output:
[690/690 09:54, Epoch 3/3]
Epoch Training Loss Validation Loss Accuracy
1 No log 2.009243 0.901881
2 No log 1.366582 0.917144
3 2.032900 1.167348 0.9209591.3. Tinh chỉnh mô hình DeiT (Data-efficient Image Transformers)
DeiT sử dụng Distillation Token để học từ một mô hình CNN giáo viên, giúp nó hiệu quả dữ liệu hơn ViT.
from transformers import DeiTForImageClassification, AutoImageProcessor
model_id = "facebook/deit-base-distilled-patch16-224"
# Tải mô hình DeiT đã pre-train
deit_model = DeiTForImageClassification.from_pretrained(model_id, num_labels=37)
deit_processor = AutoImageProcessor.from_pretrained(model_id, use_fast=True)output:
config.json: 0.00B [00:00, ?B/s]
pytorch_model.bin: 0%| | 0.00/349M [00:00<?, ?B/s]
...Định nghĩa collate_fn cho DeiT và huấn luyện:
def deit_collate_fn(batch):
images = [example["image"] for example in batch]
labels = [example["label"] for example in batch]
inputs = deit_processor(images, return_tensors="pt", do_convert_rgb=True)
inputs["labels"] = torch.tensor(labels)
return inputsfrom transformers import Trainer, TrainingArguments
args = TrainingArguments("my_pets_deit", per_device_train_batch_size=16,
eval_strategy="epoch", num_train_epochs=3,
remove_unused_columns=False,
report_to="none")
trainer = Trainer(model=deit_model, args=args, data_collator=deit_collate_fn,
train_dataset=pets["train"], eval_dataset=pets["test"],
compute_metrics=compute_accuracy)
train_output = trainer.train()output:
[690/690 09:40, Epoch 3/3]
Epoch Training Loss Validation Loss Accuracy
1 No log 0.269723 0.915781
2 No log 0.220499 0.937858
3 0.365800 0.201385 0.9441261.4. Phân vùng ảnh không giám sát sử dụng DINO
DINO (Self-Distillation with No Labels) cho phép các bản đồ chú ý (attention maps) tự động phân vùng đối tượng mà không cần nhãn.
from PIL import Image
import urllib.request
image_url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(urllib.request.urlopen(image_url))
image
from transformers import AutoImageProcessor, AutoModel
model_id = "facebook/dino-vitb8"
# output_attentions=True để lấy bản đồ chú ý
model = AutoModel.from_pretrained(model_id, output_attentions=True)
processor = AutoImageProcessor.from_pretrained(model_id, do_convert_rgb=True)output:
config.json: 0%| | 0.00/453 [00:00<?, ?B/s]
model.safetensors: 0%| | 0.00/343M [00:00<?, ?B/s]
...Trích xuất Attention Maps:
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
output = model(**inputs)
cls_token_output = output.last_hidden_state[:, 0]
cls_token_output.shapeoutput:
torch.Size([1, 768])last_layer_attention_maps = output.attentions[-1]
# LƯU Ý: Ở đây ta lấy attention của [CLS] token đối với tất cả các tokens khác
# Shape: [Batch, Num_Heads, Seq_Len, Seq_Len]
# Ta lấy [0, :, 0, 1:] nghĩa là: Batch 0, All Heads, CLS token (index 0) nhìn các token khác (1:)
cls_attn = last_layer_attention_maps[0, :, 1:, 0]
cls_attn.shapeoutput:
torch.Size([12, 784])Trực quan hóa Attention Maps:
import torchvision.transforms.functional as TF
num_heads, num_patches = cls_attn.shape
size = int(num_patches ** 0.5) # Tính kích thước cạnh của lưới patch (ví dụ 28x28)
plt.figure(figsize=(12, 7))
for head_index in range(12):
plt.subplot(3, 4, head_index + 1)
# Reshape vector attention thành lưới 2D
attn = cls_attn[head_index].reshape(size, size)
attn_map = attn.unsqueeze(0).unsqueeze(0)
# Resize bản đồ chú ý về kích thước ảnh gốc để hiển thị đè lên
attn_resized = TF.resize(attn_map, image.size[::-1],
interpolation=TF.InterpolationMode.BILINEAR)[0, 0]
plt.imshow(image)
# Hiển thị heatmap với độ trong suốt alpha=0.5
plt.imshow(attn_resized.numpy(), cmap='jet', alpha=0.5)
plt.axis('off')
plt.show()
2. Multimodal Transformers (Transformer Đa phương thức)
2.1. CLIP (Contrastive Language-Image Pre-training)
CLIP học sự liên kết giữa ảnh và văn bản thông qua Contrastive Loss. Nó cho phép thực hiện Zero-shot Classification.
from transformers import pipeline
model_id = "openai/clip-vit-base-patch32"
# Khởi tạo pipeline zero-shot classification
clip_pipeline = pipeline(task="zero-shot-image-classification", model=model_id,
device_map="auto", dtype="auto")
candidate_labels = ["cricket", "ladybug", "spider"] # Dế, Bọ rùa, Nhện
image_url = "https://homl.info/ladybug" # Một bức ảnh bọ rùa trên hoa bồ công anh
# Thực hiện phân loại
results = clip_pipeline(image_url, candidate_labels=candidate_labels,
hypothesis_template="This is a photo of a {}.")output:
config.json: 0.00B [00:00, ?B/s]
pytorch_model.bin: 0%| | 0.00/605M [00:00<?, ?B/s]
...resultsoutput:
[{'score': 0.9972853660583496, 'label': 'ladybug'},
{'score': 0.0016511697322130203, 'label': 'spider'},
{'score': 0.0010634352220222354, 'label': 'cricket'}]candidate_labels2 = ["dandelion", "lily", "poppy", "rose", "sunflower"] # Bồ công anh, Loa kèn, Anh túc, Hồng, Hướng dương
results2 = clip_pipeline(image_url, candidate_labels=candidate_labels2,
hypothesis_template="This is a photo of a {}.")
results2output:
[{'score': 0.660966694355011, 'label': 'dandelion'},
{'score': 0.30492842197418213, 'label': 'poppy'},
...]Phân tích thủ công các vector đặc trưng (Feature Embeddings)
import PIL
import urllib.request
from transformers import CLIPProcessor, CLIPModel
clip_processor = CLIPProcessor.from_pretrained(model_id)
clip_model = CLIPModel.from_pretrained(model_id)
image = PIL.Image.open(urllib.request.urlopen(image_url)).convert("RGB")
# Tạo các câu mô tả (captions)
captions = [f"This is a photo of a {label}." for label in candidate_labels]
# Tiền xử lý cả ảnh và text
inputs = clip_processor(text=captions, images=[image], return_tensors="pt",
padding=True)
with torch.no_grad():
outputs = clip_model(**inputs)
text_features = outputs.text_embeds # shape [3, 512] # 3 captions
image_features = outputs.image_embeds # shape [1, 512] # 1 ảnh (bọ rùa)output:
Using a slow image processor as `use_fast` is unset...image_features.shapeoutput:
torch.Size([1, 512])text_features.shapeoutput:
torch.Size([3, 512])image_features.norm(dim=1)output:
tensor([1.])text_features.norm(dim=1)output:
tensor([1.0000, 1.0000, 1.0000])similarities = image_features @ text_features.T # shape [1, 3]
similaritiesoutput:
tensor([[0.2337, 0.3021, 0.2381]])Tính xác suất với logit_scale (temperature):
temperature = clip_model.logit_scale.detach().exp()
rescaled_similarities = similarities * temperature
probabilities = torch.nn.functional.softmax(rescaled_similarities , dim=1)
probabilitiesoutput:
tensor([[0.0011, 0.9973, 0.0017]])temperatureoutput:
tensor(100.0000)Mã hóa riêng biệt với get_image_features và get_text_features:
from transformers import CLIPTokenizer, CLIPImageProcessor, CLIPModel
from PIL import Image
import urllib.request
model_id = "openai/clip-vit-base-patch32"
clip_tokenizer = CLIPTokenizer.from_pretrained(model_id)
clip_image_processor = CLIPImageProcessor.from_pretrained(model_id)
clip_model = CLIPModel.from_pretrained(model_id)
image = Image.open(urllib.request.urlopen(image_url)).convert("RGB")
image_inputs = clip_image_processor(images=image, return_tensors="pt")
with torch.no_grad():
image_features = clip_model.get_image_features(**image_inputs) # [1, 512]
# Tự chuẩn hóa L2
image_features /= image_features.norm(dim=1, keepdim=True)
captions = [f"This is a photo of a {label}." for label in candidate_labels]
text_inputs = clip_tokenizer(captions, padding=True, return_tensors="pt")
with torch.no_grad():
text_features = clip_model.get_text_features(**text_inputs) # [3, 512]
# Tự chuẩn hóa L2
text_features /= text_features.norm(dim=1, keepdim=True)similarities = image_features @ text_features.T
temperature = clip_model.logit_scale.detach().exp()
rescaled_similarities = similarities * temperature
probabilities = torch.nn.functional.softmax(rescaled_similarities , dim=1)
probabilitiesoutput:
tensor([[0.0011, 0.9973, 0.0017]])2.2. Perceiver và Fourier Positional Encoding
Fourier Positional Encoding giúp mạng nơ-ron học các đặc trưng tần số cao (chi tiết sắc nét).
class FourierPositionalEncoding(nn.Module):
def __init__(self, num_bands, max_resolution):
super().__init__()
self.num_bands = num_bands # Số lượng dải tần số (K trong công thức)
self.max_resolution = max_resolution # Độ phân giải tối đa (μ)
# Tạo các tần số rải đều từ 1.0 đến max_resolution/2
frequencies = torch.linspace(1.0, max_resolution / 2, steps=num_bands)
self.register_buffer("frequencies", frequencies)
def forward(self, X):
# X shape: [..., d] (d=2 cho ảnh 2D, d=3 cho video)
out = [X]
for freq in self.frequencies:
angles = torch.pi * freq * X
out += [angles.sin(), angles.cos()]
return torch.cat(out, dim=-1) # output shape: [..., d * (2K + 1)]Thử nghiệm và trực quan hóa:
H, W = 224, 224
num_bands = 6
# Tạo lưới tọa độ chuẩn hóa [-1, 1]
coords_y = torch.linspace(-1, 1, H)
coords_x = torch.linspace(-1, 1, W)
grid_y, grid_x = torch.meshgrid(coords_y, coords_x, indexing="ij")
pos = torch.stack([grid_x, grid_y], dim=-1) # shape [H, W, 2]
fourier_pos_enc = FourierPositionalEncoding(num_bands=num_bands, max_resolution=H)
pos_encodings = fourier_pos_enc(pos)titles = ["x", "y"]
for f in range(1, 6+1):
titles += [f"$sin(\pi f_{f}x)$", f"$sin(\pi f_{f}y)$", f"$cos(\pi f_{f}x)$", f"$cos(\pi f_{f}y)$"]
plt.figure(figsize=(6, 8))
for dim in range(26):
# Sắp xếp lại vị trí vẽ để nhóm các tần số giống nhau
plt.subplot(8, 4, dim + 1 + (2 if dim > 1 else 0))
plt.imshow(pos_encodings[..., dim])
plt.title(titles[dim], fontsize=10)
plt.axis("off")
plt.tight_layout()
plt.show()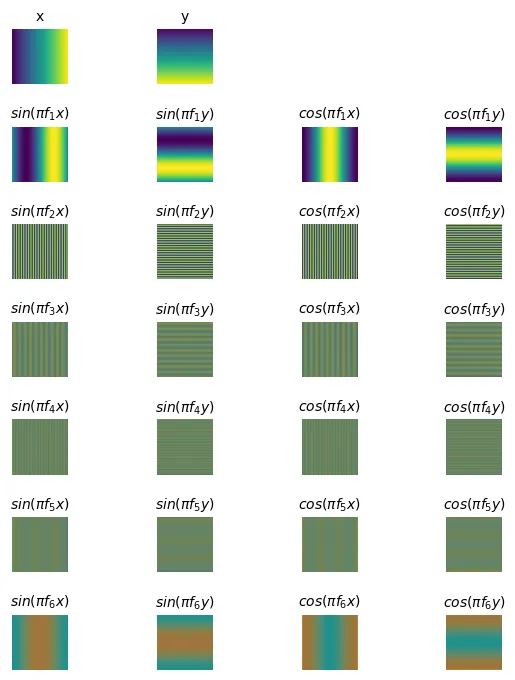
from sklearn.datasets import load_sample_image
plt.imshow(load_sample_image("flower.jpg"))
2.3. BLIP-2 (Bootstrapping Language-Image Pre-training)
BLIP-2 cho phép sinh văn bản từ hình ảnh (Image Captioning, VQA) bằng cách kết nối LLM với Vision Encoder thông qua Q-Former.
from transformers import Blip2Processor, Blip2ForConditionalGeneration
model_id = "Salesforce/blip2-opt-2.7b"
blip2_processor = Blip2Processor.from_pretrained(model_id)
# Sử dụng float16 để tiết kiệm bộ nhớ GPU
blip2_model = Blip2ForConditionalGeneration.from_pretrained(
model_id, device_map=device, dtype=torch.float16)
image_url = "http://images.cocodataset.org/val2017/000000039769.jpg" # ảnh hai con mèo
image = Image.open(urllib.request.urlopen(image_url))
inputs = blip2_processor(images=image, return_tensors="pt")
inputs = inputs.to(device, dtype=torch.float16)
with torch.no_grad():
generated_ids = blip2_model.generate(**inputs)
generated_text = blip2_processor.batch_decode(generated_ids)output:
preprocessor_config.json: 0%| | 0.00/432 [00:00<?, ?B/s]
...generated_textoutput:
['<image><image>...</s>two cats laying on a couch\n']generated_text = blip2_processor.batch_decode(generated_ids,
skip_special_tokens=True)
generated_textoutput:
['two cats laying on a couch\n']2.4. Google Gemini
Sử dụng Google GenAI SDK để gọi API của mô hình đa phương thức Gemini.
if IS_COLAB:
from google.colab import userdata
# Lấy API key từ secrets của Colab
gemini_api_key = userdata.get('gemini_api_key')
else:
# Đọc key từ file nếu chạy local
try:
gemini_api_key = open("gemini_api_key.secret").read().strip()
except FileNotFoundError:
print("Vui lòng cung cấp Gemini API Key.")
gemini_api_key = "YOUR_API_KEY_HERE" # Thay thế bằng key của bạnimage_url = "http://images.cocodataset.org/val2017/000000039769.jpg" # hai con mèo
image = Image.open(urllib.request.urlopen(image_url))
image.save("my_cats_photo.jpg")from google import genai
try:
gemini_client = genai.Client(api_key=gemini_api_key)
# Upload file lên server của Google
cats_photo = gemini_client.files.upload(file="my_cats_photo.jpg")
question = "What animal and how many? Format: [animal, number]"
# Gửi prompt kèm ảnh
response = gemini_client.models.generate_content(
model="gemini-2.5-flash", # hoặc "gemini-2.5-pro"
contents=[cats_photo, question])
print(response.text)
except Exception as e:
print(f"Lỗi khi gọi Gemini API: {e}")
print("Đảm bảo bạn đã cài đặt thư viện 'google-genai' và có API key hợp lệ.")output:
[cat, 2]