[DL101] Chương 7: Transformer cho Xử lý Ngôn ngữ Tự nhiên và Chatbot
Kiến trúc Transformer, BERT, GPT và cách xây dựng Chatbot
Bài viết có tham khảo, sử dụng và sửa đổi tài nguyên từ kho lưu trữ handson-mlp, tuân thủ giấy phép Apache‑2.0. Chúng tôi chân thành cảm ơn tác giả Aurélien Géron (@aureliengeron) vì sự chia sẻ kiến thức tuyệt vời và những đóng góp quý giá cho cộng đồng.
Ở chương này, chúng ta sẽ khám phá một trong những kiến trúc có ảnh hưởng rất lớn trong Deep Learning hiện đại: Transformer.
Sự ra đời của Transformer đã đánh dấu một bước ngoặt lớn trong Xử lý Ngôn ngữ Tự nhiên (NLP). Nó thay thế hoàn toàn các mạng hồi quy (RNN/LSTM) vốn gặp khó khăn trong việc xử lý các chuỗi dài và không thể tính toán song song. Sức mạnh của Transformer đến từ cơ chế Self-Attention (Tự chú ý), cho phép mô hình “nhìn” vào toàn bộ câu cùng một lúc và hiểu mối quan hệ giữa các từ bất kể khoảng cách của chúng.
Trong chương này, chúng ta sẽ xây dựng một Transformer từ con số 0 để hiểu rõ từng chi tiết toán học bên trong, sau đó ứng dụng các mô hình ngôn ngữ lớn (LLM) hiện đại như GPT và Mistral để xây dựng các ứng dụng thực tế.
Bạn có thể chạy trực tiếp các đoạn mã code tại: Google Colab.
Cài đặt môi trường
Kiểm tra phiên bản Python:
import sys
# Kiểm tra phiên bản Python phải từ 3.10 trở lên
assert sys.version_info >= (3, 10)Xác định môi trường thực thi:
IS_COLAB = "google.colab" in sys.modules
IS_KAGGLE = "kaggle_secrets" in sys.modulesCài đặt và cập nhật các thư viện cần thiết:
if IS_COLAB:
%pip install -qU torchmetrics
if IS_KAGGLE:
%pip install -qU transformersoutput:
[?25l [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [32m0.0/983.2 kB [0m [31m? [0m eta [36m-:--:-- [0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [32m983.2/983.2 kB [0m [31m58.3 MB/s [0m eta [36m0:00:00 [0m
[?25hKiểm tra phiên bản PyTorch (yêu cầu tối thiểu 2.6.0 để hỗ trợ các tối ưu hóa mới nhất cho Transformer):
from packaging.version import Version
import torch
assert Version(torch.__version__) >= Version("2.6.0")Cấu hình phần cứng: Transformer yêu cầu tính toán ma trận khổng lồ. GPU là bắt buộc để huấn luyện hiệu quả.
if torch.cuda.is_available():
device = "cuda"
elif torch.backends.mps.is_available():
device = "mps"
else:
device = "cpu"
deviceoutput:
'cuda'Cảnh báo nếu không có GPU:
if device == "cpu":
print("Neural nets can be very slow without a hardware accelerator.")
if IS_COLAB:
print("Go to Runtime > Change runtime and select a GPU hardware "
"accelerator.")
if IS_KAGGLE:
print("Go to Settings > Accelerator and select GPU.")Cấu hình hiển thị biểu đồ:
import matplotlib.pyplot as plt
plt.rc('font', size=14)
plt.rc('axes', labelsize=14, titlesize=14)
plt.rc('legend', fontsize=14)
plt.rc('xtick', labelsize=10)
plt.rc('ytick', labelsize=10)Chúng ta xây dựng lại các hàm tiện ích train và evaluate_tm để tái sử dụng.
import torchmetrics
def evaluate_tm(model, data_loader, metric):
model.eval()
metric.reset()
with torch.no_grad():
for X_batch, y_batch in data_loader:
X_batch, y_batch = X_batch.to(device), y_batch.to(device)
y_pred = model(X_batch)
metric.update(y_pred, y_batch)
return metric.compute()
def train(model, optimizer, loss_fn, metric, train_loader, valid_loader,
n_epochs, patience=2, factor=0.5, epoch_callback=None):
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer, mode="max", patience=patience, factor=factor)
history = {"train_losses": [], "train_metrics": [], "valid_metrics": []}
for epoch in range(n_epochs):
total_loss = 0.0
metric.reset()
model.train()
if epoch_callback is not None:
epoch_callback(model, epoch)
for index, (X_batch, y_batch) in enumerate(train_loader):
X_batch, y_batch = X_batch.to(device), y_batch.to(device)
y_pred = model(X_batch)
loss = loss_fn(y_pred, y_batch)
total_loss += loss.item()
loss.backward()
optimizer.step()
optimizer.zero_grad()
metric.update(y_pred, y_batch)
train_metric = metric.compute().item()
print(f"\rBatch {index + 1}/{len(train_loader)}", end="")
print(f", loss={total_loss/(index+1):.4f}", end="")
print(f", {train_metric=:.2%}", end="")
history["train_losses"].append(total_loss / len(train_loader))
history["train_metrics"].append(train_metric)
val_metric = evaluate_tm(model, valid_loader, metric).item()
history["valid_metrics"].append(val_metric)
scheduler.step(val_metric)
print(f"\rEpoch {epoch + 1}/{n_epochs}, "
f"train loss: {history['train_losses'][-1]:.4f}, "
f"train metric: {history['train_metrics'][-1]:.2%}, "
f"valid metric: {history['valid_metrics'][-1]:.2%}")
return historyHàm quản lý bộ nhớ:
import gc
def del_vars(variable_names=[]):
for name in variable_names:
try:
del globals()[name]
except KeyError:
pass
gc.collect()
if device == "cuda":
torch.cuda.empty_cache()1. Chuẩn bị dữ liệu Dịch máy (Neural Machine Translation - NMT)
Chúng ta sẽ sử dụng bộ dữ liệu song ngữ Anh-Tây Ban Nha từ dự án Tatoeba.
import torch.nn as nn
from datasets import load_dataset
from torch.utils.data import random_split, DataLoader
import tokenizers# Tải bộ dữ liệu Tatoeba Anh-Tây Ban Nha
nmt_original_valid_set, nmt_test_set = load_dataset(
path="ageron/tatoeba_mt_train", name="eng-spa",
split=["validation", "test"])
# Chia tập validation gốc thành train (80%) và validation (20%) mới
split = nmt_original_valid_set.train_test_split(train_size=0.8, seed=42)
nmt_train_set, nmt_valid_set = split["train"], split["test"]output:
README.md: 0.00B [00:00, ?B/s]
...
Generating test split: 0%| | 0/24514 [00:00<?, ? examples/s]Xây dựng Tokenizer sử dụng thuật toán BPE (Byte-Pair Encoding):
def train_eng_spa(): # Hàm generator để duyệt qua toàn bộ văn bản huấn luyện
for pair in nmt_train_set:
yield pair["source_text"]
yield pair["target_text"]
max_length = 500
vocab_size = 10_000
# Sử dụng mô hình BPE (Byte-Pair Encoding)
nmt_tokenizer_model = tokenizers.models.BPE(unk_token="<unk>")
nmt_tokenizer = tokenizers.Tokenizer(nmt_tokenizer_model)
# Cấu hình padding và cắt ngắn (truncation)
nmt_tokenizer.enable_padding(pad_id=0, pad_token="<pad>")
nmt_tokenizer.enable_truncation(max_length=max_length)
# Tiền xử lý: tách từ theo khoảng trắng
nmt_tokenizer.pre_tokenizer = tokenizers.pre_tokenizers.Whitespace()
# Huấn luyện tokenizer
nmt_tokenizer_trainer = tokenizers.trainers.BpeTrainer(
vocab_size=vocab_size, special_tokens=["<pad>", "<unk>", "<s>", "</s>"])
nmt_tokenizer.train_from_iterator(train_eng_spa(), nmt_tokenizer_trainer)Định nghĩa cấu trúc dữ liệu và hàm collate_fn để chuẩn bị batch:
from collections import namedtuple
# Định nghĩa cấu trúc dữ liệu cho một cặp input NMT
fields = ["src_token_ids", "src_mask", "tgt_token_ids", "tgt_mask"]
class NmtPair(namedtuple("NmtPairBase", fields)):
def to(self, device):
return NmtPair(self.src_token_ids.to(device), self.src_mask.to(device),
self.tgt_token_ids.to(device), self.tgt_mask.to(device))def nmt_collate_fn(batch):
# Lấy danh sách câu nguồn và câu đích
src_texts = [pair['source_text'] for pair in batch]
# Thêm token bắt đầu <s> và kết thúc </s> cho câu đích
tgt_texts = [f"<s> {pair['target_text']} </s>" for pair in batch]
# Mã hóa thành ID
src_encodings = nmt_tokenizer.encode_batch(src_texts)
tgt_encodings = nmt_tokenizer.encode_batch(tgt_texts)
# Chuyển đổi sang Tensor
src_token_ids = torch.tensor([enc.ids for enc in src_encodings])
tgt_token_ids = torch.tensor([enc.ids for enc in tgt_encodings])
# Tạo Attention Mask (0 cho padding, 1 cho token thật)
src_mask = torch.tensor([enc.attention_mask for enc in src_encodings])
tgt_mask = torch.tensor([enc.attention_mask for enc in tgt_encodings])
# Inputs cho decoder: bỏ token cuối cùng (</s>) - Teacher Forcing
inputs = NmtPair(src_token_ids, src_mask,
tgt_token_ids[:, :-1], tgt_mask[:, :-1])
# Labels cần dự đoán: bỏ token đầu tiên (<s>)
labels = tgt_token_ids[:, 1:]
return inputs, labels
batch_size = 64
nmt_train_loader = DataLoader(nmt_train_set, batch_size=batch_size,
collate_fn=nmt_collate_fn, shuffle=True)
nmt_valid_loader = DataLoader(nmt_valid_set, batch_size=batch_size,
collate_fn=nmt_collate_fn)
nmt_test_loader = DataLoader(nmt_test_set, batch_size=batch_size,
collate_fn=nmt_collate_fn)2. Attention Is All You Need: Kiến trúc Transformer Nguyên bản
Mô hình Transformer loại bỏ hoàn toàn hồi quy (recurrence), thay vào đó sử dụng cơ chế Self-Attention để tính toán biểu diễn của mỗi từ dựa trên mối quan hệ với tất cả các từ khác trong câu.
2.1. Positional Encodings (Mã hóa vị trí)
Vì Transformer xử lý song song, nó không có khái niệm về thứ tự. Ta phải cộng thêm thông tin vị trí vào embedding của từ.
import torch
import torch.nn as nn
import torch.nn.functional as F
class PositionalEmbedding(nn.Module):
def __init__(self, max_length, embed_dim, dropout=0.1):
super().__init__()
# Tạo một ma trận tham số ngẫu nhiên cho vị trí, sẽ được học trong quá trình huấn luyện
self.pos_embed = nn.Parameter(torch.randn(max_length, embed_dim) * 0.02)
self.dropout = nn.Dropout(dropout)
def forward(self, X):
# Cộng embedding của từ (X) với embedding vị trí tương ứng
return self.dropout(X + self.pos_embed[:X.size(1)])embed_dim = 512
pos_embedding = PositionalEmbedding(max_length, embed_dim)
embeddings = torch.randn(256, 500, 512) # Giả lập input embedding
embeddings_with_pos = pos_embedding(embeddings)
embeddings_with_pos.shapeoutput:
torch.Size([256, 500, 512])2.2. Multi-Head Attention (Cơ chế Chú ý Đa đầu)
Công thức tính Attention:
Multi-Head Attention chia nhỏ vector embedding thành nhiều phần (heads) và tính attention song song trên mỗi phần, giúp mô hình học được nhiều khía cạnh khác nhau của mối quan hệ từ ngữ.
class MultiheadAttention(nn.Module):
def __init__(self, embed_dim, num_heads, dropout=0.1):
super().__init__()
self.h = num_heads
self.d = embed_dim // num_heads # Kích thước của mỗi head
# Các lớp tuyến tính để chiếu Q, K, V
self.q_proj = nn.Linear(embed_dim, embed_dim)
self.k_proj = nn.Linear(embed_dim, embed_dim)
self.v_proj = nn.Linear(embed_dim, embed_dim)
self.out_proj = nn.Linear(embed_dim, embed_dim)
self.dropout = nn.Dropout(dropout)
def split_heads(self, X):
# Chia chiều embedding thành (num_heads, head_dim) và đảo vị trí để tính toán song song
# Shape: (Batch, Seq_Len, Heads, Head_Dim) -> (Batch, Heads, Seq_Len, Head_Dim)
return X.view(X.size(0), X.size(1), self.h, self.d).transpose(1, 2)
def forward(self, query, key, value, attn_mask=None, key_padding_mask=None):
# 1. Chiếu tuyến tính và chia heads
q = self.split_heads(self.q_proj(query)) # (B, h, Lq, d)
k = self.split_heads(self.k_proj(key)) # (B, h, Lk, d)
v = self.split_heads(self.v_proj(value)) # (B, h, Lv, d) với Lv=Lk
# 2. Scaled Dot-Product Attention
# Tính scores: Q @ K.T
scores = q @ k.transpose(2, 3) / self.d**0.5 # (B, h, Lq, Lk)
# 3. Áp dụng Mask (nếu có)
if attn_mask is not None:
# Che các vị trí tương lai (cho decoder) hoặc các vị trí không mong muốn
scores = scores.masked_fill(attn_mask, -torch.inf)
if key_padding_mask is not None:
# Che các token padding để không tính attention vào đó
mask = key_padding_mask.unsqueeze(1).unsqueeze(2) # (B, 1, 1, Lk)
scores = scores.masked_fill(mask, -torch.inf)
# 4. Softmax và tính tổng có trọng số
weights = scores.softmax(dim=-1) # (B, h, Lq, Lk)
Z = self.dropout(weights) @ v # (B, h, Lq, d)
# 5. Ghép các heads lại (Concatenate)
Z = Z.transpose(1, 2) # (B, Lq, h, d)
Z = Z.reshape(Z.size(0), Z.size(1), self.h * self.d) # (B, Lq, h × d)
# 6. Phép chiếu cuối cùng
return (self.out_proj(Z), weights)2.3. Xây dựng các khối Transformer
Encoder Layer: Gồm Self-Attention và Feed Forward Network.
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1):
super().__init__()
# Lớp Self-Attention
self.self_attn = MultiheadAttention(d_model, nhead, dropout)
# Mạng Feed Forward
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
# Chuẩn hóa lớp
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, src, src_mask=None, src_key_padding_mask=None):
# Sublayer 1: Self-Attention
# src đóng vai trò là Q, K, V (vì là self-attention)
attn, _ = self.self_attn(src, src, src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)
Z = self.norm1(src + self.dropout(attn)) # Add & Norm
# Sublayer 2: Feed Forward
ff = self.dropout(self.linear2(self.dropout(self.linear1(Z).relu())))
return self.norm2(Z + ff) # Add & NormDecoder Layer: Gồm Masked Self-Attention, Cross-Attention (với Encoder output) và Feed Forward Network.
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1):
super().__init__()
# 1. Masked Self-Attention (cho decoder input)
self.self_attn = MultiheadAttention(d_model, nhead, dropout)
# 2. Cross-Attention (giữa decoder và encoder output)
self.multihead_attn = MultiheadAttention(d_model, nhead, dropout)
self.dropout = nn.Dropout(dropout)
# 3. Feed Forward
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.linear2 = nn.Linear(dim_feedforward, d_model)
# Các lớp Norm
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
def forward(self, tgt, memory, tgt_mask=None, memory_mask=None,
tgt_key_padding_mask=None, memory_key_padding_mask=None):
# 1. Self-Attention
attn1, _ = self.self_attn(tgt, tgt, tgt,
attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)
Z = self.norm1(tgt + self.dropout(attn1))
# 2. Cross-Attention: Q=Z (từ decoder), K=V=memory (từ encoder)
attn2, _ = self.multihead_attn(Z, memory, memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)
Z = self.norm2(Z + self.dropout(attn2))
# 3. Feed Forward
ff = self.dropout(self.linear2(self.dropout(self.linear1(Z).relu())))
return self.norm3(Z + ff)Ghép nối thành mô hình hoàn chỉnh:
from copy import deepcopy
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers, norm=None):
super().__init__()
# Tạo bản sao của encoder_layer num_layers lần
self.layers = nn.ModuleList([deepcopy(encoder_layer)
for _ in range(num_layers)])
self.norm = norm
def forward(self, src, mask=None, src_key_padding_mask=None):
Z = src
for layer in self.layers:
Z = layer(Z, mask, src_key_padding_mask)
if self.norm is not None:
Z = self.norm(Z)
return Zclass TransformerDecoder(nn.Module):
def __init__(self, decoder_layer, num_layers, norm=None):
super().__init__()
self.layers = nn.ModuleList([deepcopy(decoder_layer)
for _ in range(num_layers)])
self.norm = norm
def forward(self, tgt, memory, tgt_mask=None, memory_mask=None,
tgt_key_padding_mask=None, memory_key_padding_mask=None):
Z = tgt
for layer in self.layers:
Z = layer(Z, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask)
if self.norm is not None:
Z = self.norm(Z)
return Zclass Transformer(nn.Module):
def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1):
super().__init__()
# Khởi tạo Encoder
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,
dropout)
norm1 = nn.LayerNorm(d_model)
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers,
norm1)
# Khởi tạo Decoder
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,
dropout)
norm2 = nn.LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers,
norm2)
def forward(self, src, tgt, src_mask=None, tgt_mask=None, memory_mask=None,
src_key_padding_mask=None, tgt_key_padding_mask=None,
memory_key_padding_mask=None):
# Bước 1: Mã hóa nguồn
memory = self.encoder(src, src_mask, src_key_padding_mask)
# Bước 2: Giải mã đích (sử dụng memory từ encoder)
output = self.decoder(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask)
return output3. Xây dựng Transformer Dịch Anh-Tây Ban Nha
Chúng ta sẽ sử dụng lớp nn.Transformer có sẵn của PyTorch để tối ưu hiệu năng (nó được viết bằng C++).
class NmtTransformer(nn.Module):
def __init__(self, vocab_size, max_length, embed_dim=512, pad_id=0,
num_heads=8, num_layers=6, dropout=0.1):
super().__init__()
# Embedding cho từ vựng
self.embed = nn.Embedding(vocab_size, embed_dim, padding_idx=pad_id)
# Positional Embedding (học được)
self.pos_embed = PositionalEmbedding(max_length, embed_dim, dropout)
# Mô hình Transformer của PyTorch
self.transformer = nn.Transformer(
embed_dim, num_heads, num_encoder_layers=num_layers,
num_decoder_layers=num_layers, batch_first=True)
# Lớp đầu ra dự đoán từ tiếp theo
self.output = nn.Linear(embed_dim, vocab_size)
def forward(self, pair):
# Nhúng và thêm vị trí cho nguồn và đích
src_embeds = self.pos_embed(self.embed(pair.src_token_ids))
tgt_embeds = self.pos_embed(self.embed(pair.tgt_token_ids))
# Tạo mask cho padding (True là vị trí cần che)
src_pad_mask = ~pair.src_mask.bool()
tgt_pad_mask = ~pair.tgt_mask.bool()
# Tạo causal mask cho decoder (ma trận tam giác trên)
# Để ngăn decoder nhìn thấy tương lai
size = [pair.tgt_token_ids.size(1)] * 2
full_mask = torch.full(size, True, device=tgt_pad_mask.device)
causal_mask = torch.triu(full_mask, diagonal=1)
# Lan truyền qua Transformer
out_decoder = self.transformer(src_embeds, tgt_embeds,
src_key_padding_mask=src_pad_mask,
memory_key_padding_mask=src_pad_mask,
tgt_mask=causal_mask, #tgt_is_causal=True (PyTorch 2.x)
tgt_key_padding_mask=tgt_pad_mask)
# Chiếu về kích thước vocab
return self.output(out_decoder).permute(0, 2, 1)Minh họa Causal Mask:
torch.triu(torch.full((5, 5), True), diagonal=1)output:
tensor([[False, True, True, True, True],
[False, False, True, True, True],
[False, False, False, True, True],
[False, False, False, False, True],
[False, False, False, False, False]])# Hàm tiện ích của PyTorch để tạo mask tương tự
nn.Transformer.generate_square_subsequent_mask(5)output:
tensor([[0., -inf, -inf, -inf, -inf],
[0., 0., -inf, -inf, -inf],
[0., 0., 0., -inf, -inf],
[0., 0., 0., 0., -inf],
[0., 0., 0., 0., 0.]])Huấn luyện mô hình:
torch.manual_seed(42)
# Khởi tạo mô hình
nmt_tr_model = NmtTransformer(vocab_size, max_length, embed_dim=128, pad_id=0,
num_heads=4, num_layers=2, dropout=0.1).to(device)
if device == "mps":
# WORKAROUND: Trên thiết bị MPS (Mac), nn.Transformer có thể bị lỗi
# nên ta thay thế bằng class Transformer tự viết ở trên.
nmt_tr_model.transformer = Transformer(
embed_dim=128, num_heads=4, num_encoder_layers=2, num_decoder_layers=2)
n_epochs = 20
# Hàm mất mát CrossEntropy, bỏ qua token padding
xentropy = nn.CrossEntropyLoss(ignore_index=0)
optimizer = torch.optim.NAdam(nmt_tr_model.parameters())
accuracy = torchmetrics.Accuracy(task="multiclass", num_classes=vocab_size)
accuracy = accuracy.to(device)
# Bắt đầu huấn luyện
history = train(nmt_tr_model, optimizer, xentropy, accuracy,
nmt_train_loader, nmt_valid_loader, n_epochs)output:
Batch 2467/2467, loss=4.0449, train_metric=10.56%
Epoch 1/20, train loss: 4.0449, train metric: 10.56%, valid metric: 13.94%
...
Epoch 20/20, train loss: 1.5443, train metric: 19.73%, valid metric: 20.53%torch.save(nmt_tr_model.state_dict(), "my_nmt_tr_model.pt")Dịch văn bản (Inference): Quá trình dịch yêu cầu sinh từng từ một (auto-regressive).
def translate(model, src_text, max_length=20, pad_id=0, eos_id=3):
tgt_text = ""
token_ids = []
for index in range(max_length):
# Chuẩn bị batch giả lập với target text hiện tại
batch, _ = nmt_collate_fn([{"source_text": src_text,
"target_text": tgt_text}])
with torch.no_grad():
Y_logits = model(batch.to(device))
Y_token_ids = Y_logits.argmax(dim=1) # Chọn token có xác suất cao nhất (Greedy Decoding)
next_token_id = Y_token_ids[0, index] # Lấy token vừa sinh ra
next_token = nmt_tokenizer.id_to_token(next_token_id)
tgt_text += " " + next_token
if next_token_id == eos_id: # Dừng nếu gặp </s>
break
return tgt_textnmt_tr_model.eval()
translate(nmt_tr_model, "I like to play soccer with my friends at the beach")output:
' Me gusta jugar fútbol con mis amigos en la playa . </s>'del accuracy, history, nmt_test_set, nmt_tokenizer
del nmt_tokenizer_model, nmt_test_loader, nmt_train_loader, nmt_valid_loader
del nmt_tr_model, nmt_train_set, nmt_valid_set, optimizer
del pos_embedding, xentropy
del_vars([])4. Transformer chỉ dùng Encoder (Encoder-Only)
BERT là đại diện tiêu biểu cho nhóm này, chuyên dùng cho các tác vụ hiểu ngôn ngữ.
from transformers import BertConfig, BertForMaskedLM, BertTokenizerFast
# Tải tokenizer của BERT
bert_tokenizer = BertTokenizerFast.from_pretrained("bert-base-uncased")
# Cấu hình mô hình BERT nhỏ để demo
config = BertConfig( # Tùy chỉnh theo ngân sách huấn luyện
vocab_size=bert_tokenizer.vocab_size, hidden_size=128, num_hidden_layers=2,
num_attention_heads=4, intermediate_size=512, max_position_embeddings=128)
bert = BertForMaskedLM(config)output:
tokenizer_config.json: 0%| | 0.00/48.0 [00:00<?, ?B/s]
vocab.txt: 0%| | 0.00/232k [00:00<?, ?B/s]
tokenizer.json: 0%| | 0.00/466k [00:00<?, ?B/s]
config.json: 0%| | 0.00/570 [00:00<?, ?B/s]Huấn luyện Masked Language Model (MLM):
from datasets import load_dataset
def tokenize(example, tokenizer=bert_tokenizer):
return tokenizer(example["text"], truncation=True, max_length=128,
padding="max_length")
# Tải và xử lý dữ liệu WikiText
mlm_dataset = load_dataset("wikitext", "wikitext-2-raw-v1", split="train")
mlm_dataset = mlm_dataset.map(tokenize, batched=True)output:
README.md: 0.00B [00:00, ?B/s]
...
Map: 0%| | 0/36718 [00:00<?, ? examples/s]from transformers import Trainer, TrainingArguments
from transformers import DataCollatorForLanguageModeling
# Cấu hình huấn luyện
args = TrainingArguments(output_dir="./my_bert", num_train_epochs=5,
per_device_train_batch_size=16,
report_to="none")
# Data Collator tự động che (mask) 15% số token
mlm_collator = DataCollatorForLanguageModeling(bert_tokenizer, mlm=True,
mlm_probability=0.15)
# Sử dụng Trainer API của HuggingFace
trainer = Trainer(model=bert, args=args, train_dataset=mlm_dataset,
data_collator=mlm_collator)
trainer_output = trainer.train()output:
[11475/11475 05:44, Epoch 5/5]
Step Training Loss
500 8.887800
...
11000 6.963100from transformers import pipeline
torch.manual_seed(42)
# Sử dụng pipeline để điền từ vào chỗ trống
fill_mask = pipeline("fill-mask", model=bert, tokenizer=bert_tokenizer)
top_predictions = fill_mask("The capital of [MASK] is Rome.")
top_predictions[0]output:
Device set to use cuda:0
{'score': 0.051636673510074615,
'token': 1010,
'token_str': ',',
'sequence': 'the capital of, is rome.'}del_vars(["bert_tokenizer", "config", "bert", "mlm_dataset", "args",
"mlm_collator", "trainer", "trainer_output", "fill_mask",
"top_predictions"])4.1. Sử dụng BERT để lấy embedding
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModel.from_pretrained("bert-base-uncased")
inputs = tokenizer(["I like soccer", "Hello, World!"],
padding=True, return_tensors="pt")
outputs = model(**inputs)
# Lấy embedding của token [CLS] (vị trí 0)
cls_embedding = outputs.last_hidden_state[:, 0, :]
cls_embedding.shapeoutput:
model.safetensors: 0%| | 0.00/440M [00:00<?, ?B/s]
torch.Size([2, 768])del tokenizer, model, inputs, outputs, cls_embedding
del_vars([])4.2. Sentence Transformers (Mạng Siamese)
from sentence_transformers import SentenceTransformer
# Tải mô hình đã pre-train
model = SentenceTransformer("all-MiniLM-L6-v2")
sentences = ["She's shopping", "She bought some shoes", "She's working"]
# Mã hóa câu thành vector
embeddings = model.encode(sentences, convert_to_tensor=True)
# Tính độ tương đồng giữa các câu
similarities = model.similarity(embeddings, embeddings)output:
modules.json: 0%| | 0.00/349 [00:00<?, ?B/s]
...
config.json: 0%| | 0.00/190 [00:00<?, ?B/s]similaritiesoutput:
tensor([[1.0000, 0.6328, 0.5841],
[0.6328, 1.0000, 0.3831],
[0.5841, 0.3831, 1.0000]], device='cuda:0')del_vars(["model", "sentences", "embeddings", "similarities"])5. Transformer chỉ dùng Decoder (Decoder-Only)
GPT là đại diện tiêu biểu, dùng cho sinh văn bản.
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "gpt2"
gpt2_tokenizer = AutoTokenizer.from_pretrained(model_id)
# device_map="auto" giúp tự động phân bổ mô hình lên GPU/CPU
gpt2 = AutoModelForCausalLM.from_pretrained(
model_id, device_map="auto", dtype="auto")5.1. Chiến lược sinh văn bản (Text Generation Strategies)
def generate(model, tokenizer, prompt, max_new_tokens=50, **generate_kwargs):
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=max_new_tokens,
pad_token_id=tokenizer.eos_token_id,
**generate_kwargs)
return tokenizer.decode(outputs[0], skip_special_tokens=True)prompt = "Scientists found a talking unicorn today. Here's the full story:"
# Mặc định là Greedy (hoặc Beam Search tùy cấu hình)
generate(gpt2, gpt2_tokenizer, prompt)output:
"Scientists found a talking unicorn today. Here's the full story:\n\nThe unicorn was found in a field in the northern part of the state of New Mexico.\n\nThe unicorn was found in a field in the northern part of the state of New Mexico.\n\nThe unicorn was found in a field in"torch.manual_seed(42)
# Sử dụng Sampling (do_sample=True)
generate(gpt2, gpt2_tokenizer, prompt, do_sample=True)output:
"Scientists found a talking unicorn today. Here's the full story:\n\nThere aren't lots of other unicorns and they have been making their way across the United States since at least the 1800s, but this year there weren't a solitary unicorn on the land. Today, there are around 1,000."torch.manual_seed(42)
# Sử dụng Top-p Sampling
generate(gpt2, gpt2_tokenizer, prompt, do_sample=True, top_p=0.6)output:
"Scientists found a talking unicorn today. Here's the full story:\n\nThe unicorn is an amphibian found in the Middle East, and it is not known where it came from.\n\nThe researchers said they discovered the unicorn in Egypt in a cave in the desert of the Sinai Peninsula.\n\nThe researchers"5.2. Zero-shot Learning (Học không cần mẫu)
DEFAULT_TEMPLATE = "Capital city of France = Paris\nCapital city of {country} ="
def get_capital_city(model, tokenizer, country, template=DEFAULT_TEMPLATE):
prompt = template.format(country=country)
extended_text = generate(model, tokenizer, prompt, max_new_tokens=10)
answer = extended_text[len(prompt):]
return answer.strip().splitlines()[0].strip()get_capital_city(gpt2, gpt2_tokenizer, "United Kingdom")output:
'London'get_capital_city(gpt2, gpt2_tokenizer, "Mexico")output:
'Mexico City'del model_id, gpt2
del_vars([])6. Mô hình lớn hơn: Mistral-7B
Sử dụng Mistral-7B cho kết quả tốt hơn.
if IS_COLAB:
from google.colab import userdata
access_token = userdata.get('token-hf-read-mistral')
else:
# Đọc token từ file nếu chạy local
access_token = open("/content/hf-read-mistral.secret").read().strip()
# access_token = "..." # Hoặc điền trực tiếp (không khuyến khích)from huggingface_hub import login
login(access_token)model_id = "mistralai/Mistral-7B-v0.3"
mistral7b_tokenizer = AutoTokenizer.from_pretrained(model_id)
mistral7b = AutoModelForCausalLM.from_pretrained(
model_id, device_map="auto", dtype="auto")torch.manual_seed(42)
generate(mistral7b, mistral7b_tokenizer, prompt, do_sample=True, top_p=0.6)output:
'Scientists found a talking unicorn today. Here\'s the full story:\n\n> A group of scientists discovered a talking unicorn in the jungles of Peru, which they believe to be the first of its kind.\n>\n> "We have always known that unicorns were real," said'6.1. Xây dựng Chatbot đơn giản
class BobTheChatbot:
def __init__(self, model, tokenizer, introduction=bob_introduction,
max_answer_length=10_000):
self.model = model
self.tokenizer = tokenizer
self.context = introduction
self.max_answer_length = max_answer_length
def chat(self, prompt):
# Cập nhật ngữ cảnh với câu hỏi mới
self.context += "\nMe: " + prompt + "\nBob:"
context = self.context
start_index = len(context)
while True:
# Sinh câu trả lời
extended = generate(self.model, self.tokenizer, context,
max_new_tokens=100)
answer = extended[start_index:]
# Điều kiện dừng: mô hình bắt đầu tự đóng vai "Me:" hoặc lặp lại
if ("\nMe: " in answer or extended == context or
len(answer) >= self.max_answer_length): break
context = extended
# Lấy phần trả lời của Bob
answer = answer.split("\nMe: ")[0]
self.context += answer
return answer.strip()7. Direct Preference Optimization (DPO)
DPO giúp căn chỉnh mô hình theo sở thích con người (preference data).
# Cài đặt hàm loss DPO thủ công để hiểu rõ
def sum_of_log_probas(model, tokenizer, full_inputs):
encodings = tokenizer(
full_inputs, return_tensors="pt", padding=True).to(model.device)
logits = model(**encodings).logits
next_token_log_probas = -F.cross_entropy(
logits[:, :-1].permute(0, 2, 1), encodings.input_ids[:, 1:],
reduction="none")
return (next_token_log_probas * encodings.attention_mask[:, :-1]).sum(dim=1)
def dpo_loss(model, ref_model, tokenizer, full_input_c, full_input_r, beta=0.1):
# Tính log proba trên mô hình hiện tại
p_c = sum_of_log_probas(model, tokenizer, full_input_c)
p_r = sum_of_log_probas(model, tokenizer, full_input_r)
# Tính log proba trên mô hình tham chiếu (đóng băng)
with torch.no_grad():
p_ref_c = sum_of_log_probas(ref_model, tokenizer, full_input_c)
p_ref_r = sum_of_log_probas(ref_model, tokenizer, full_input_r)
# Công thức Loss DPO
return -F.logsigmoid(beta*((p_c - p_ref_c) - (p_r - p_ref_r))).mean()del_vars(["access_token", "answer", "answer_log_proba", "bad_bob", "bob",
"bob_introduction", "encodings", "extended_text", "full_input",
"full_prompt", "i", "log_probas", "log_probas_sum", "logits",
"mistral7b", "mistral7b_tokenizer", "model_id", "next_token_ids",
"next_token_log_probas", "padding_mask", "prompt", "token_index",
"topk", "v"])8. Fine-Tuning với thư viện TRL (Transformer Reinforcement Learning)
Sử dụng thư viện trl để thực hiện SFT và DPO dễ dàng hơn.
8.1. SFT trên tập dữ liệu Alpaca
sft_dataset = load_dataset("tatsu-lab/alpaca", split="train")def preprocess(example):
# Định dạng lại dữ liệu theo cấu trúc hội thoại
text = f"Human: {example['instruction']}\n"
if example['input'] != "":
text += f"-> {example['input']}\n"
text += f"\nAssistant: {example['output']}"
return {"text": text}
sft_dataset = sft_dataset.map(preprocess)if IS_COLAB or IS_KAGGLE:
%pip install -qU trlfrom trl import SFTTrainer, SFTConfig
sft_model_dir = "./my_gpt2_sft_alpaca"
training_args = SFTConfig(
output_dir=sft_model_dir, max_length=512,
per_device_train_batch_size=4, num_train_epochs=1, save_steps=50,
logging_steps=10, learning_rate=5e-5, report_to="none")
# SFTTrainer tự động lo việc tokenize và training loop
sft_trainer = SFTTrainer("gpt2", train_dataset=sft_dataset, args=training_args)
sft_train_output = sft_trainer.train()
sft_trainer.model.save_pretrained(sft_model_dir)del sft_dataset, training_args, sft_trainer, sft_train_output
del_vars([])8.2. DPO trên tập dữ liệu Preference
pref_dataset = load_dataset("Anthropic/hh-rlhf", split="train")from trl import DPOConfig, DPOTrainer
dpo_model_dir = "./my_gpt2_sft_alpaca_dpo_hh_rlhf"
training_args = DPOConfig(
output_dir=dpo_model_dir, max_length=512, per_device_train_batch_size=4,
num_train_epochs=1, save_steps=50, logging_steps=10, learning_rate=2e-5,
report_to="none")
gpt2_tokenizer.pad_token = gpt2_tokenizer.eos_token
# DPOTrainer yêu cầu mô hình đã qua SFT
dpo_trainer = DPOTrainer(
sft_model_dir, args=training_args, train_dataset=pref_dataset,
processing_class=gpt2_tokenizer)
dpo_train_output = dpo_trainer.train()
dpo_trainer.model.save_pretrained(dpo_model_dir)del_vars(["dpo_model_dir", "dpo_train_output", "dpo_trainer", "gpt2_tokenizer",
"pref_dataset", "sft_model_dir", "training_args"])9. Sử dụng mô hình Chatbot có sẵn (Instruct Model)
Dùng các mô hình Instruct đã được fine-tune sẵn.
model_id = "mistralai/Mistral-7B-Instruct-v0.3"
mistral7bi_tokenizer = AutoTokenizer.from_pretrained(model_id)
mistral7bi = AutoModelForCausalLM.from_pretrained(
model_id, device_map="auto", dtype="auto")good_bob = BobTheChatbot(mistral7bi, mistral7bi_tokenizer)
print(good_bob.chat("Tell me 5 jokes"))output:
Sure, here are five jokes for you:
...del good_bob, mistral7bi, mistral7bi_tokenizer, model_id
del_vars([])Phụ lục: Fixed Positional Encodings
Trong bài báo gốc, tác giả sử dụng các hàm sin và cos cố định thay vì embedding học được.
class PositionalEncoding(nn.Module):
def __init__(self, max_length, embed_dim, dropout=0.1):
super().__init__()
p = torch.arange(max_length).unsqueeze(1)
i = torch.arange(0, embed_dim, 2)
angle = p / 10_000 ** (i / embed_dim)
pos_encodings = torch.empty(max_length, embed_dim)
pos_encodings[:, ::2] = angle.sin()
pos_encodings[:, 1::2] = angle.cos()
# register_buffer giúp lưu tensor vào state_dict nhưng không phải là tham số cần học
self.register_buffer("pos_encodings", pos_encodings)
self.dropout = nn.Dropout(dropout)
def forward(self, X):
return self.dropout(X + self.pos_encodings[:X.size(1)])figure_max_length = 201
figure_enc_size = 512
pos_enc = PositionalEncoding(figure_max_length, figure_enc_size)
P = pos_enc.pos_encodings.numpy()
i1, i2, crop_i = 100, 101, 150
p1, p2, p3 = 22, 60, 35
fig, (ax1, ax2) = plt.subplots(nrows=2, ncols=1, sharex=True, figsize=(9, 5))
img = ax1.imshow(P.T[:crop_i], cmap="gray", interpolation="bilinear", aspect="auto")
# ... (vẽ biểu đồ)
plt.show()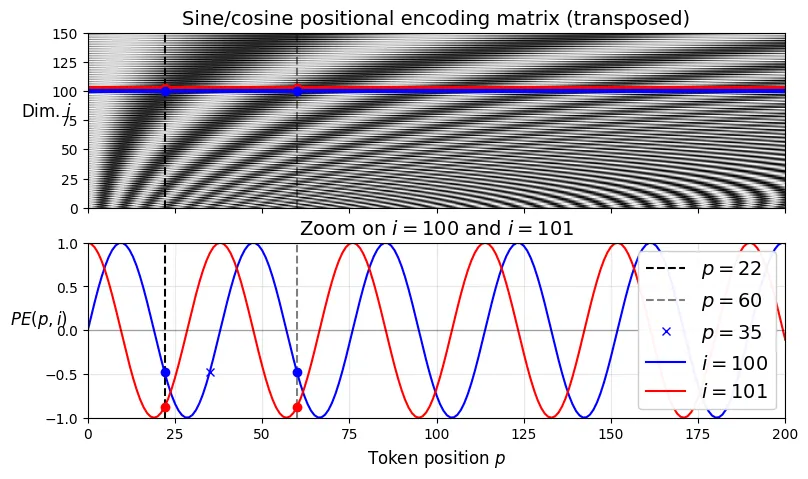
del_vars(["max_length", "embed_dim", "pos_encoding", "embeddings",
"embeddings_with_pos", "figure_max_length", "figure_enc_size",
"pos_enc", "P", "i1", "i2", "crop_i", "p1", "p2", "p3", "fig",
"ax1", "ax2", "img", "cheat"])