[DL101] Chương 5: Xử lý dữ liệu dạng chuỗi sử dụng RNN và CNN
Recurrent Neural Networks (RNN), LSTM, GRU và xử lý dữ liệu chuỗi
Bài viết có tham khảo, sử dụng và sửa đổi tài nguyên từ kho lưu trữ handson-mlp, tuân thủ giấy phép Apache‑2.0. Chúng tôi chân thành cảm ơn tác giả Aurélien Géron (@aureliengeron) vì sự chia sẻ kiến thức tuyệt vời và những đóng góp quý giá cho cộng đồng.
Ở chương này, chúng ta sẽ khám phá một trong những lĩnh vực thú vị và thử thách: Xử lý Dữ liệu Chuỗi (Sequence Processing).
Dữ liệu chuỗi không chỉ đơn thuần là tập hợp các điểm dữ liệu rời rạc; nó chứa đựng thông tin về thứ tự, sự phụ thuộc thời gian và ngữ cảnh. Ví dụ, Một mô hình dự báo thời tiết không thể đảo lộn thứ tự các ngày trong tuần, cũng như một hệ thống dịch máy không thể xáo trộn từ ngữ trong câu. Để giải quyết vấn đề này, chúng ta cần những kiến trúc đặc biệt có khả năng “nhớ” quá khứ để dự đoán tương lai.
Trong chương này, chúng ta sẽ đi từ những khái niệm cơ bản nhất về chuỗi thời gian, xây dựng các mạng RNN thủ công để hiểu rõ bản chất toán học, và tiến tới các kiến trúc hiện đại như LSTM, GRU và WaveNet để giải quyết các bài toán phức tạp như dự báo đa biến và sáng tác nhạc.
Bạn có thể chạy trực tiếp các đoạn mã code tại: Google Colab.
Cấu hình môi trường (Setup)
Kiểm tra phiên bản Python:
import sys
# Kiểm tra phiên bản Python hệ thống phải lớn hơn hoặc bằng 3.10
assert sys.version_info >= (3, 10)Xác định môi trường thực thi:
IS_COLAB = "google.colab" in sys.modules
IS_KAGGLE = "kaggle_secrets" in sys.modulesCài đặt thư viện bổ trợ torchmetrics:
if IS_COLAB:
%pip install -q torchmetricsoutput:
[?25l [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [32m0.0/983.2 kB [0m [31m? [0m eta [36m-:--:-- [0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [32m983.2/983.2 kB [0m [31m53.0 MB/s [0m eta [36m0:00:00 [0m
[?25hKiểm tra phiên bản PyTorch:
from packaging.version import Version
import torch
# Kiểm tra phiên bản PyTorch
assert Version(torch.__version__) >= Version("2.6.0")Cấu hình thiết bị tính toán (Device): Mạng RNN thực hiện các phép tính tuần tự, tuy nhiên các phép nhân ma trận bên trong mỗi bước vẫn được hưởng lợi lớn từ GPU.
if torch.cuda.is_available():
device = "cuda" # Sử dụng GPU NVIDIA
elif torch.backends.mps.is_available():
device = "mps" # Sử dụng Metal Performance Shaders trên macOS
else:
device = "cpu" # Sử dụng CPU nếu không có GPU
deviceoutput:
'cuda'Cảnh báo nếu không có GPU:
if device == "cpu":
print("Neural nets can be very slow without a hardware accelerator.")
if IS_COLAB:
print("Go to Runtime > Change runtime and select a GPU hardware "
"accelerator.")
if IS_KAGGLE:
print("Go to Settings > Accelerator and select GPU.")Cấu hình hiển thị biểu đồ:
import matplotlib.pyplot as plt
plt.rc('font', size=14)
plt.rc('axes', labelsize=14, titlesize=14)
plt.rc('legend', fontsize=14)
plt.rc('xtick', labelsize=10)
plt.rc('ytick', labelsize=10)Huấn luyện Mạng Nơ-ron Hồi quy (Training RNNs)
Dự báo Chuỗi thời gian (Forecasting a Time Series)
Chúng ta sẽ sử dụng bộ dữ liệu thực tế về lượng hành khách sử dụng phương tiện công cộng tại Chicago để minh họa. Đây là bài toán dự báo chuỗi thời gian đơn biến (univariate) và đa biến (multivariate).
from pathlib import Path
import pandas as pd
import tarfile
import urllib.request
def download_and_extract_ridership_data():
tarball_path = Path("datasets/ridership.tgz")
if not tarball_path.is_file():
Path("datasets").mkdir(parents=True, exist_ok=True)
url = "https://github.com/ageron/data/raw/main/ridership.tgz"
urllib.request.urlretrieve(url, tarball_path)
with tarfile.open(tarball_path) as housing_tarball:
housing_tarball.extractall(path="datasets", filter="data")
download_and_extract_ridership_data()Tiền xử lý dữ liệu (Data Preprocessing)
import pandas as pd
from pathlib import Path
path = Path("datasets/ridership/CTA_-_Ridership_-_Daily_Boarding_Totals.csv")
df = pd.read_csv(path, parse_dates=["service_date"])
df.columns = ["date", "day_type", "bus", "rail", "total"] # Đổi tên cột ngắn gọn hơn
df = df.sort_values("date").set_index("date")
df = df.drop("total", axis=1) # Không cần cột tổng, vì nó là bus + rail
df = df.drop_duplicates() # Loại bỏ các tháng bị trùng lặp (2011-10 và 2014-07)df.head()output:
day_type bus rail
date
2001-01-01 U 297192 126455
2001-01-02 W 780827 501952
2001-01-03 W 824923 536432
2001-01-04 W 870021 550011
2001-01-05 W 890426 557917Trực quan hóa dữ liệu:
import matplotlib.pyplot as plt
# Vẽ biểu đồ lượng khách từ tháng 3 đến tháng 5 năm 2019
df["2019-03":"2019-05"].plot(grid=True, marker=".", figsize=(8, 3.5))
plt.show()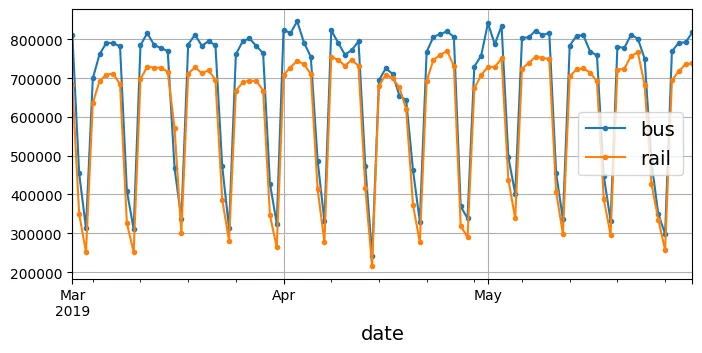
Tính dừng (Stationarity) và Phân biệt (Differencing)
Để loại bỏ tính mùa vụ (seasonality) và xu hướng (trend), giúp chuỗi thời gian trở nên “dừng” (stationary - các đặc tính thống kê như mean, variance không đổi theo thời gian), chúng ta sử dụng kỹ thuật phân biệt (differencing).
Ở đây, chúng ta dùng sai phân bậc 1 với độ trễ 7 ngày (diff(7)) để loại bỏ tính mùa vụ theo tuần.
# Tính sự khác biệt (diff) với độ trễ 7 ngày
diff_7 = df[["bus", "rail"]].diff(7)["2019-03":"2019-05"]
fig, axs = plt.subplots(2, 1, sharex=True, figsize=(8, 5))
df.plot(ax=axs[0], legend=False, marker=".") # Chuỗi thời gian gốc
df.shift(7).plot(ax=axs[0], grid=True, legend=False, linestyle=":") # Dữ liệu trễ 7 ngày
diff_7.plot(ax=axs[1], grid=True, marker=".") # Chuỗi thời gian sau khi lấy hiệu 7 ngày
axs[0].set_ylim([170_000, 900_000]) # Giới hạn trục y để biểu đồ đẹp hơn
plt.show()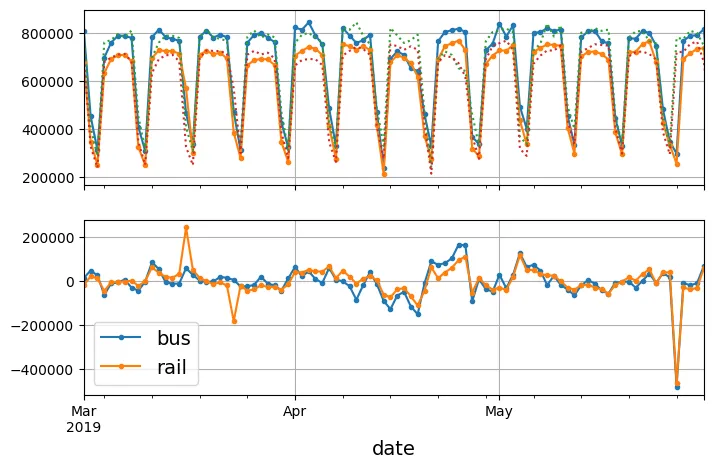
list(df.loc["2019-05-25":"2019-05-27"]["day_type"])output:
['A', 'U', 'U']Các chỉ số đánh giá (Evaluation Metrics)
- Mean Absolute Error (MAE): Trung bình sai số tuyệt đối.
- Mean Absolute Percentage Error (MAPE): Trung bình phần trăm sai số.
Dự báo ngây thơ (Naive Forecasting): Giả sử giá trị ngày mai bằng giá trị hôm nay (hoặc tuần trước). Đây là baseline quan trọng.
diff_7.abs().mean()output:
bus 43915.608696
rail 42143.271739
dtype: float64targets = df[["bus", "rail"]]["2019-03":"2019-05"]
(diff_7 / targets).abs().mean()output:
bus 0.082938
rail 0.089948
dtype: float64Phân tích xu hướng dài hạn bằng trung bình trượt (rolling average):
period = slice("2001", "2019")
df_monthly = df.select_dtypes(include="number").resample('ME').mean()
rolling_average_12_months = df_monthly.loc[period].rolling(window=12).mean()
fig, ax = plt.subplots(figsize=(8, 4))
df_monthly[period].plot(ax=ax, marker=".")
rolling_average_12_months.plot(ax=ax, grid=True, legend=False)
plt.show()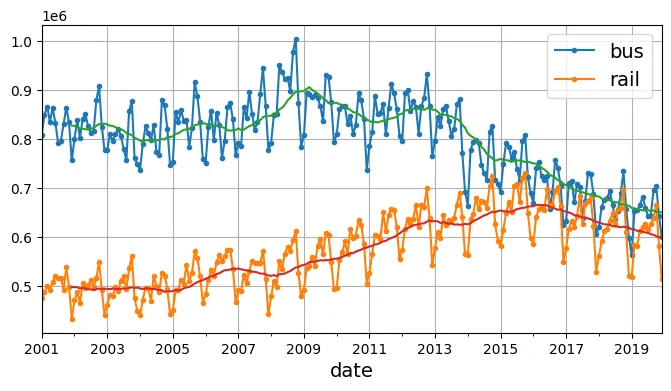
# Vẽ biểu đồ sau khi loại bỏ tính mùa vụ 12 tháng
df_monthly.diff(12)[period].plot(grid=True, marker=".", figsize=(8, 3))
plt.show()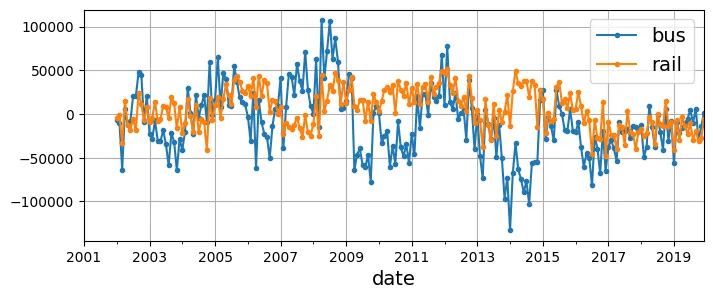
Họ mô hình ARMA (The ARMA Model Family)
SARIMA (Seasonal AutoRegressive Integrated Moving Average) là công cụ thống kê mạnh mẽ cho chuỗi thời gian có tính mùa vụ.
if IS_COLAB:
%pip install -q -U statsmodelsfrom statsmodels.tsa.arima.model import ARIMA
origin, today = "2019-01-01", "2019-05-31"
rail_series = df.loc[origin:today]["rail"].asfreq("D")
# Khởi tạo và huấn luyện mô hình SARIMA(1, 0, 0)(0, 1, 1)[7]
# order=(p, d, q), seasonal_order=(P, D, Q, s)
model = ARIMA(rail_series,
order=(1, 0, 0),
seasonal_order=(0, 1, 1, 7))
model = model.fit()
y_pred = model.forecast() # Dự báo một bước thời gian tiếp theo (trả về 427,758.6)y_pred.iloc[0] # Kết quả dự báo của ARIMAoutput:
np.float64(427758.6262875742)df["rail"].loc["2019-06-01"] # Giá trị thực tế (Target value)output:
np.int64(379044)df["rail"].loc["2019-05-25"] # Dự báo ngây thơ (Naive forecast - giá trị của 1 tuần trước)output:
np.int64(426932)Dự báo cuốn chiếu (Rolling Forecast) để đánh giá mô hình trên một khoảng thời gian:
origin, start_date, end_date = "2019-01-01", "2019-03-01", "2019-05-31"
time_period = pd.date_range(start_date, end_date)
rail_series = df.loc[origin:end_date]["rail"].asfreq("D")
y_preds = []
# Vòng lặp dự báo cuốn chiếu (rolling forecast)
for today in time_period.shift(-1):
model = ARIMA(rail_series[origin:today], # Huấn luyện trên dữ liệu tính đến "today"
order=(1, 0, 0),
seasonal_order=(0, 1, 1, 7))
model = model.fit() # Lưu ý: chúng ta huấn luyện lại mô hình mỗi ngày!
y_pred = model.forecast().iloc[0]
y_preds.append(y_pred)
y_preds = pd.Series(y_preds, index=time_period)
mae = (y_preds - rail_series[time_period]).abs().mean() # Trả về khoảng 32,040.7maeoutput:
np.float64(32040.72009292839)# Code bổ sung – hiển thị kết quả dự báo của SARIMA
fig, ax = plt.subplots(figsize=(8, 3))
rail_series.loc[time_period].plot(label="True", ax=ax, marker=".", grid=True)
ax.plot(y_preds, color="r", marker=".", label="SARIMA Forecasts")
plt.legend()
plt.show()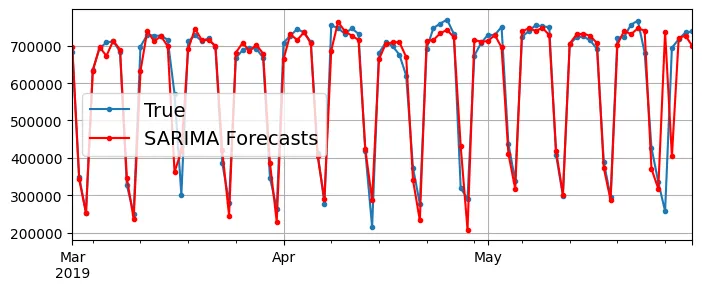
Biểu đồ tự tương quan (ACF) và tự tương quan riêng phần (PACF) giúp xác định tham số cho ARIMA.
# Code bổ sung – hiển thị cách vẽ Autocorrelation Function (ACF) và
# Partial Autocorrelation Function (PACF)
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
fig, axs = plt.subplots(nrows=1, ncols=2, figsize=(15, 5))
plot_acf(df[period]["rail"], ax=axs[0], lags=35)
axs[0].grid()
plot_pacf(df[period]["rail"], ax=axs[1], lags=35, method="ywm")
axs[1].grid()
plt.show()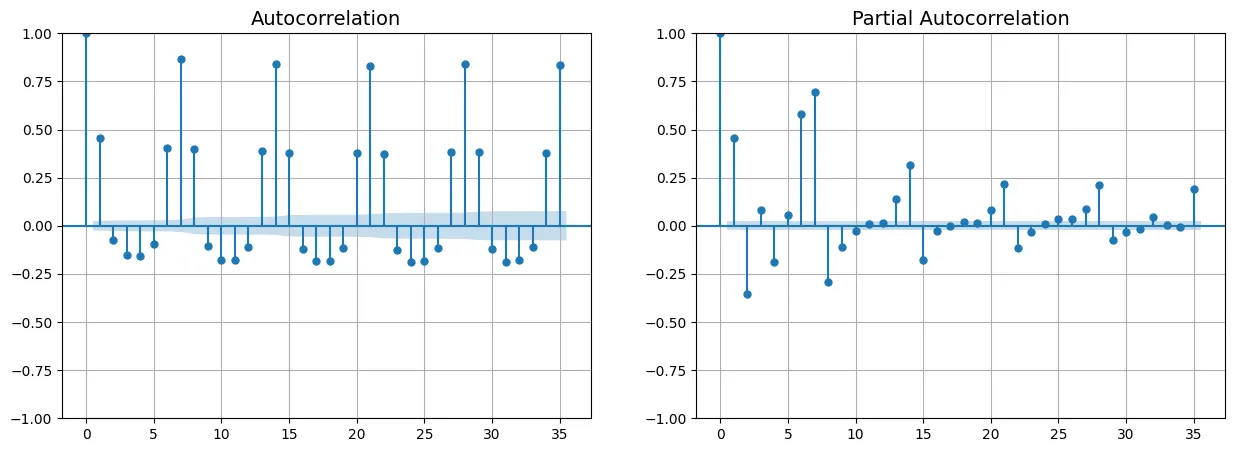
Chuẩn bị Dữ liệu cho các Mô hình Học máy (Machine Learning)
Chuyển đổi chuỗi thời gian thành bài toán Supervised Learning bằng phương pháp Sliding Window.
class TimeSeriesDataset(torch.utils.data.Dataset):
def __init__(self, series, window_length):
self.series = series
self.window_length = window_length
def __len__(self):
return len(self.series) - self.window_length
def __getitem__(self, idx):
if idx >= len(self):
raise IndexError("dataset index out of range")
end = idx + self.window_length # Chỉ số đầu tiên sau cửa sổ
window = self.series[idx : end]
target = self.series[end]
return window, target# Ví dụ minh họa hoạt động của Dataset
my_series = torch.tensor([[0], [1], [2], [3], [4], [5]])
my_dataset = TimeSeriesDataset(my_series, window_length=3)
for window, target in my_dataset:
print("Window:", window, " Target:", target)output:
Window: tensor([[0],
[1],
[2]]) Target: tensor([3])
Window: tensor([[1],
[2],
[3]]) Target: tensor([4])
Window: tensor([[2],
[3],
[4]]) Target: tensor([5])from torch.utils.data import DataLoader
torch.manual_seed(0)
# Sử dụng DataLoader để tạo batch ngẫu nhiên
my_loader = DataLoader(my_dataset, batch_size=2, shuffle=True)
for X, y in my_loader:
print("X:", X, " y:", y)output:
X: tensor([[[0],
[1],
[2]],
[[2],
[3],
[4]]]) y: tensor([[3],
[5]])
X: tensor([[[1],
[2],
[3]]]) y: tensor([[4]])Chia tập dữ liệu (Lưu ý: Không shuffle theo thời gian khi split):
# Chia dữ liệu và chuẩn hóa (chia cho 1 triệu để đưa về khoảng giá trị nhỏ)
rail_train = torch.FloatTensor(df[["rail"]]["2016-01":"2018-12"].values / 1e6)
rail_valid = torch.FloatTensor(df[["rail"]]["2019-01":"2019-05"].values / 1e6)
rail_test = torch.FloatTensor(df[["rail"]]["2019-06":].values / 1e6)window_length = 56
train_set = TimeSeriesDataset(rail_train, window_length)
train_loader = DataLoader(train_set, batch_size=32, shuffle=True)
valid_set = TimeSeriesDataset(rail_valid, window_length)
valid_loader = DataLoader(valid_set, batch_size=32)
test_set = TimeSeriesDataset(rail_test, window_length)
test_loader = DataLoader(test_set, batch_size=32)Xây dựng hàm huấn luyện tổng quát:
import torchmetrics
def evaluate_tm(model, data_loader, metric):
model.eval()
metric.reset()
with torch.no_grad():
for X_batch, y_batch in data_loader:
X_batch, y_batch = X_batch.to(device), y_batch.to(device)
y_pred = model(X_batch)
metric.update(y_pred, y_batch)
return metric.compute()
def train(model, optimizer, loss_fn, metric, train_loader, valid_loader,
n_epochs, patience=10, factor=0.1):
# Scheduler để giảm learning rate khi loss không cải thiện
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer, mode="min", patience=patience, factor=factor)
history = {"train_losses": [], "train_metrics": [], "valid_metrics": []}
for epoch in range(n_epochs):
total_loss = 0.0
metric.reset()
model.train()
for X_batch, y_batch in train_loader:
X_batch, y_batch = X_batch.to(device), y_batch.to(device)
y_pred = model(X_batch)
loss = loss_fn(y_pred, y_batch)
total_loss += loss.item()
loss.backward()
optimizer.step()
optimizer.zero_grad()
metric.update(y_pred, y_batch)
history["train_losses"].append(total_loss / len(train_loader))
history["train_metrics"].append(metric.compute().item())
val_metric = evaluate_tm(model, valid_loader, metric).item()
history["valid_metrics"].append(val_metric)
scheduler.step(val_metric)
print(f"Epoch {epoch + 1}/{n_epochs}, "
f"train loss: {history['train_losses'][-1]:.4f}, "
f"train metric: {history['train_metrics'][-1]:.4f}, "
f"valid metric: {history['valid_metrics'][-1]:.4f}")
return historyThử nghiệm với mô hình tuyến tính (Linear Model) làm baseline:
import torch.nn as nn
import torchmetrics
torch.manual_seed(42)
# Mô hình tuyến tính đơn giản: Flatten -> Linear
model = nn.Sequential(nn.Flatten(), nn.Linear(window_length, 1)).to(device)
loss_fn = nn.HuberLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.003, momentum=0.9)
metric = torchmetrics.MeanAbsoluteError().to(device)
history = train(model, optimizer, loss_fn, metric, train_loader,
valid_loader, n_epochs=50)output:
Epoch 1/50, train loss: 0.0154, train metric: 0.1458, valid metric: 0.1235
...
Epoch 50/50, train loss: 0.0032, train metric: 0.0485, valid metric: 0.0377evaluate_tm(model, valid_loader, metric).item() * 1e6 # Chuyển về đơn vị gốc (lượt khách)output:
37725.720554590225Sử dụng Mạng Hồi quy Đơn giản (Using a Simple RNN)
RNN xử lý dữ liệu theo thời gian, với công thức trạng thái ẩn: .
class SimpleRnnModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.hidden_size = hidden_size
# Tự định nghĩa một RNN Cell thủ công để hiểu bản chất
self.memory_cell = nn.Sequential(
nn.Linear(input_size + hidden_size, hidden_size),
nn.Tanh()
)
self.output = nn.Linear(hidden_size, output_size)
def forward(self, X):
batch_size, window_length, dimensionality = X.shape
X_time_first = X.transpose(0, 1) # Chuyển thành [Time, Batch, Features]
H = torch.zeros(batch_size, self.hidden_size, device=X.device)
for X_t in X_time_first:
XH = torch.cat((X_t, H), dim=1) # Nối input và hidden state cũ
H = self.memory_cell(XH) # Tính hidden state mới
return self.output(H)
torch.manual_seed(42)
model = SimpleRnnModel(input_size=1, hidden_size=32, output_size=1).to(device)# Code bổ sung – định nghĩa hàm tiện ích dùng lại nhiều lần
def fit_and_evaluate(model, train_loader, valid_loader, lr, n_epochs=50,
patience=20, factor=0.1):
loss_fn = nn.HuberLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=0.95)
metric = torchmetrics.MeanAbsoluteError().to(device)
history = train(model, optimizer, loss_fn, metric,
train_loader, valid_loader, n_epochs=n_epochs,
patience=patience, factor=factor)
return min(history["valid_metrics"]) * 1e6torch.manual_seed(42)
univar_model = SimpleRnnModel(input_size=1, hidden_size=32, output_size=1)
univar_model = univar_model.to(device)
fit_and_evaluate(univar_model, train_loader, valid_loader, lr=0.05, n_epochs=50)output:
Epoch 1/50, train loss: 0.0523, train metric: 0.2600, valid metric: 0.2126
...
Epoch 50/50, train loss: 0.0029, train metric: 0.0506, valid metric: 0.0584
30511.001124978065Sử dụng module nn.RNN tối ưu hóa của PyTorch:
class SimpleRnnModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
# Sử dụng nn.RNN của PyTorch
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.output = nn.Linear(hidden_size, output_size)
def forward(self, X):
outputs, last_state = self.rnn(X)
# Chỉ lấy đầu ra ở bước thời gian cuối cùng để dự đoán
return self.output(outputs[:, -1])torch.manual_seed(42)
univar_model = SimpleRnnModel(input_size=1, hidden_size=32, output_size=1)
univar_model = univar_model.to(device)
fit_and_evaluate(univar_model, train_loader, valid_loader, lr=0.05, n_epochs=50)output:
Epoch 1/50, train loss: 0.0487, train metric: 0.2535, valid metric: 0.1329
...
Epoch 50/50, train loss: 0.0023, train metric: 0.0380, valid metric: 0.0321
30659.63089466095Mạng RNN Sâu (Deep RNNs)
Chồng nhiều lớp RNN lên nhau để học các đặc trưng phức tạp hơn. num_layers chỉ định số tầng.
class DeepRnnModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers):
super().__init__()
self.rnn = nn.RNN(input_size, hidden_size, num_layers=num_layers,
batch_first=True)
self.output = nn.Linear(hidden_size, output_size)
def forward(self, X):
outputs, last_state = self.rnn(X)
return self.output(outputs[:, -1])torch.manual_seed(42)
deep_model = DeepRnnModel(
input_size=1, hidden_size=32, output_size=1, num_layers=3).to(device)
fit_and_evaluate(deep_model, train_loader, valid_loader, lr=0.07, n_epochs=50)output:
Epoch 1/50, train loss: 0.0632, train metric: 0.2830, valid metric: 0.2212
...
Epoch 50/50, train loss: 0.0029, train metric: 0.0455, valid metric: 0.0318
29407.726600766182Chuỗi thời gian Đa biến (Multivariate Time Series)
Thêm các đặc trưng (features) khác vào đầu vào: lượng khách xe buýt, loại ngày (ngày thường/cuối tuần).
df_mulvar = df[["rail", "bus"]] / 1e6 # Sử dụng cả rail và bus làm đầu vào
df_mulvar["next_day_type"] = df["day_type"].shift(-1) # Biết trước loại ngày mai
df_mulvar = pd.get_dummies(df_mulvar, dtype=float) # One-hot encoding cho loại ngàymulvar_train = torch.FloatTensor(df_mulvar["2016-01":"2018-12"].values)
mulvar_valid = torch.FloatTensor(df_mulvar["2019-01":"2019-05"].values)
mulvar_test = torch.FloatTensor(df_mulvar["2019-06":].values)class MulvarTimeSeriesDataset(TimeSeriesDataset):
def __getitem__(self, idx):
window, target = super().__getitem__(idx)
# Target chỉ là cột đầu tiên (rail)
return window, target[:1]window_length = 56
mulvar_train_set = MulvarTimeSeriesDataset(mulvar_train, window_length)
mulvar_train_loader = DataLoader(mulvar_train_set, batch_size=32, shuffle=True)
mulvar_valid_set = MulvarTimeSeriesDataset(mulvar_valid, window_length)
mulvar_valid_loader = DataLoader(mulvar_valid_set, batch_size=32)
mulvar_test_set = MulvarTimeSeriesDataset(mulvar_test, window_length)
mulvar_test_loader = DataLoader(mulvar_test_set, batch_size=32)torch.manual_seed(42)
# input_size=5 vì gồm: rail, bus, và 3 cột one-hot của day_type
mulvar_model = SimpleRnnModel(input_size=5, hidden_size=32, output_size=1)
mulvar_model = mulvar_model.to(device)fit_and_evaluate(mulvar_model, mulvar_train_loader, mulvar_valid_loader, lr=0.05, n_epochs=50)output:
Epoch 1/50, train loss: 0.0652, train metric: 0.2960, valid metric: 0.0527
...
Epoch 50/50, train loss: 0.0010, train metric: 0.0297, valid metric: 0.0252
23218.054324388504Multitask Learning: Dự báo cả 2 biến (rail và bus) cùng lúc.
class MultaskTimeSeriesDataset(TimeSeriesDataset):
def __getitem__(self, idx):
window, target = super().__getitem__(idx)
return window, target[:2] # Target gồm cả rail và bus
window_length = 56
multask_train_set = MultaskTimeSeriesDataset(mulvar_train, window_length)
multask_train_loader = DataLoader(multask_train_set, batch_size=32, shuffle=True)
multask_valid_set = MultaskTimeSeriesDataset(mulvar_valid, window_length)
multask_valid_loader = DataLoader(multask_valid_set, batch_size=32)
multask_test_set = MultaskTimeSeriesDataset(mulvar_test, window_length)
multask_test_loader = DataLoader(multask_test_set, batch_size=32)
torch.manual_seed(42)
multask_model = SimpleRnnModel(input_size=5, hidden_size=32, output_size=2)
multask_model = multask_model.to(device)
fit_and_evaluate(multask_model, multask_train_loader, multask_valid_loader, lr=0.03, n_epochs=50)output:
Epoch 1/50, train loss: 0.0630, train metric: 0.2872, valid metric: 0.1379
...
Epoch 50/50, train loss: 0.0012, train metric: 0.0338, valid metric: 0.0263
24695.901200175285# Code bổ sung – đánh giá dự báo ngây thơ cho bus
bus_naive = df_mulvar["2019-01":"2019-05"]["bus"].shift(7)[window_length:]
bus_target = df_mulvar["2019-01":"2019-05"]["bus"][window_length:]
(bus_target - bus_naive).abs().mean() * 1e6output:
np.float64(43441.63157894738)# Code bổ sung – đánh giá dự báo của mô hình multitask
multask_model.eval()
Y_pred_valid = [multask_model(X.to(device)) for X, _ in multask_valid_loader]
Y_pred_valid = torch.cat(Y_pred_valid, dim=0)
Y_valid = torch.cat([Y.to(device) for _, Y in multask_valid_loader], dim=0)
for idx, name in enumerate(["bus", "rail"]):
mae = (Y_pred_valid[:, idx] - Y_valid[:, idx]).abs().mean()
print(name, int(mae * 1e6))output:
bus 26157
rail 26445Dự báo Nhiều bước (Forecasting Several Steps Ahead)
Dự báo cuốn chiếu (Autoregressive):
# Phương pháp cuốn chiếu (Autoregressive)
univar_model.eval()
n_steps = 14
with torch.no_grad():
X = rail_valid[:window_length].unsqueeze(dim=0).to(device)
for step_ahead in range(n_steps):
y_pred_one = univar_model(X)
# Nối dự đoán vào cuối và bỏ phần tử đầu tiên, tạo cửa sổ mới
X = torch.cat([X, y_pred_one.unsqueeze(dim=0)], dim=1)
Y_pred = X[0, -n_steps:, 0]# Code bổ sung – vẽ Hình 13–11
Y_pred_s = pd.Series(Y_pred.cpu() * 1e6,
index=pd.date_range("2019-02-26", "2019-03-11"))
fig, ax = plt.subplots(figsize=(8, 3.5))
df["2019-02-01":"2019-03-11"]["rail"].plot(label="True", marker=".", ax=ax)
Y_pred_s.plot(label="Predictions", grid=True, marker="x", color="r", ax=ax)
ax.vlines("2019-02-25", 0, 1e6, color="k", linestyle="--", label="Today")
ax.set_ylim([200_000, 800_000])
plt.legend(loc="center left")
plt.show()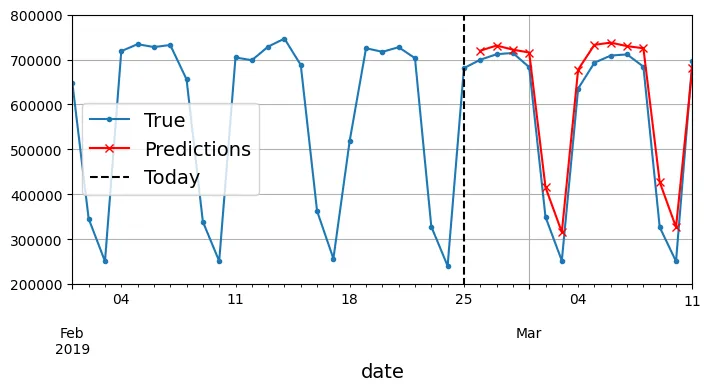
Dự báo trực tiếp (Direct Forecasting) - dự đoán vector đầu ra 14 phần tử.
class ForecastAheadDataset(TimeSeriesDataset):
def __len__(self):
# Trừ thêm 14 bước dự báo
return len(self.series) - self.window_length - 14 + 1
def __getitem__(self, idx):
end = idx + self.window_length
window = self.series[idx : end]
# Target là chuỗi 14 ngày tiếp theo của cột 0 (rail)
target = self.series[end : end + 14, 0]
return window, targetwindow_length = 56
ahead_train_set = ForecastAheadDataset(mulvar_train, window_length)
ahead_train_loader = DataLoader(ahead_train_set, batch_size=32, shuffle=True)
ahead_valid_set = ForecastAheadDataset(mulvar_valid, window_length)
ahead_valid_loader = DataLoader(ahead_valid_set, batch_size=32)
ahead_test_set = ForecastAheadDataset(mulvar_test, window_length)
ahead_test_loader = DataLoader(ahead_test_set, batch_size=32)torch.manual_seed(42)
# output_size=14: dự báo 14 ngày cùng lúc
ahead_model = SimpleRnnModel(input_size=5, hidden_size=32, output_size=14)
ahead_model = ahead_model.to(device)
fit_and_evaluate(ahead_model, ahead_train_loader, ahead_valid_loader, lr=0.05, n_epochs=50)output:
Epoch 1/50, train loss: 0.0725, train metric: 0.3051, valid metric: 0.1730
...
Epoch 50/50, train loss: 0.0033, train metric: 0.0471, valid metric: 0.0348
32948.169857263565ahead_model.eval()
with torch.no_grad():
window = mulvar_valid[:window_length] # shape [56, 5]
X = window.unsqueeze(dim=0) # shape [1, 56, 5]
Y_pred = ahead_model(X.to(device)) # shape [1, 14]Dự báo Chuỗi-sang-Chuỗi (Sequence-to-Sequence)
Dự báo tại mọi bước thời gian (từ đến ). Điều này cung cấp nhiều tín hiệu gradient hơn cho quá trình huấn luyện.
class Seq2SeqDataset(ForecastAheadDataset):
def __getitem__(self, idx):
end = idx + self.window_length
window = self.series[idx : end]
target_period = self.series[idx + 1 : end + 14, 0]
# unfold tạo ra sliding window trên tensor target
target = target_period.unfold(dimension=0, size=14, step=1)
return window, target# Minh họa hàm unfold
torch.tensor([0, 1, 2, 3, 4, 5]).unfold(dimension=0, size=4, step=1)output:
tensor([[0, 1, 2, 3],
[1, 2, 3, 4],
[2, 3, 4, 5]])window_length = 56
seq_train_set = Seq2SeqDataset(mulvar_train, window_length)
seq_train_loader = DataLoader(seq_train_set, batch_size=32, shuffle=True)
seq_valid_set = Seq2SeqDataset(mulvar_valid, window_length)
seq_valid_loader = DataLoader(seq_valid_set, batch_size=32)
seq_test_set = Seq2SeqDataset(mulvar_test, window_length)
seq_test_loader = DataLoader(seq_test_set, batch_size=32)class Seq2SeqRnnModel(SimpleRnnModel):
def forward(self, X):
outputs, last_state = self.rnn(X)
# Trả về output tại TẤT CẢ các bước thời gian, không chỉ bước cuối
return self.output(outputs)torch.matmul(torch.randn(2, 3, 5, 7), torch.randn(2, 3, 7, 11)).shapeoutput:
torch.Size([2, 3, 5, 11])torch.matmul(torch.randn(2, 3, 5, 7), torch.randn(7, 11)).shapeoutput:
torch.Size([2, 3, 5, 11])nn.Linear(32, 14)(torch.randn(10, 56, 32)).shapeoutput:
torch.Size([10, 56, 14])torch.manual_seed(42)
seq_model = Seq2SeqRnnModel(input_size=5, hidden_size=32, output_size=14)
seq_model = seq_model.to(device)
fit_and_evaluate(seq_model, seq_train_loader, seq_valid_loader, lr=1.0, n_epochs=65,
patience=5, factor=0.5)output:
Epoch 1/65, train loss: 0.0332, train metric: 0.1934, valid metric: 0.1211
...
Epoch 65/65, train loss: 0.0029, train metric: 0.0447, valid metric: 0.0479
47206.200659275055seq_model.eval()
with torch.no_grad():
some_window = mulvar_valid[:window_length] # shape [56, 5]
X = some_window.unsqueeze(dim=0) # shape [1, 56, 5]
Y_preds = seq_model(X.to(device)) # shape [1, 56, 14]
Y_pred = Y_preds[:, -1] # shape [1, 14] - Chỉ lấy dự báo cuối cùng# Đánh giá MAE theo từng bước dự báo (ngày +1, +2, ... +14)
with torch.no_grad():
X = mulvar_valid.unsqueeze(dim=0).to(device) # shape [1, 151, 5]
Y_preds_valid = seq_model(X).cpu() # shape [1, 151, 14]
for ahead in range(1, 14 + 1):
y_preds = Y_preds_valid[0, window_length : -ahead, ahead - 1]
y_true = rail_valid[window_length + ahead:, 0]
mae = (y_preds - y_true).abs().mean() * 1e6
print(f"MAE for +{ahead}:\t{mae:,.0f}")output:
MAE for +1: 23,603
...
MAE for +14: 35,938# Code bổ sung: minh họa Conv1d kernel=1 tương đương Linear
torch.manual_seed(42)
with torch.no_grad():
X = torch.randn(10, 56, 32)
conv1d = nn.Conv1d(32, 14, kernel_size=1)
linear = nn.Linear(32, 14)
linear.weight.data = conv1d.weight.squeeze(dim=2)
linear.bias.data = conv1d.bias
result1 = conv1d(X.permute(0, 2, 1)).permute(0, 2, 1)
result2 = linear(X)
torch.allclose(result1, result2, atol=1e-7)output:
TrueRNN sâu với Chuẩn hóa lớp (Deep RNNs with Layer Norm)
Để huấn luyện mạng RNN rất sâu ổn định, ta sử dụng Layer Normalization.
class SimpleRnnModelWithLN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.hidden_size = hidden_size
self.memory_cell = nn.Sequential(
nn.Linear(input_size + hidden_size, hidden_size),
nn.LayerNorm(hidden_size), # Thêm Layer Norm
nn.Tanh()
)
self.output = nn.Linear(hidden_size, output_size)
def forward(self, X):
batch_size, window_length, dimensionality = X.shape
X_time_first = X.transpose(0, 1)
H = torch.zeros(batch_size, self.hidden_size, device=X.device)
for X_t in X_time_first:
XH = torch.cat((X_t, H), dim=1)
H = self.memory_cell(XH)
return self.output(H)torch.manual_seed(42)
rnn_with_ln_model = SimpleRnnModelWithLN(input_size=5, hidden_size=32, output_size=14)
rnn_with_ln_model = rnn_with_ln_model.to(device)
fit_and_evaluate(rnn_with_ln_model, ahead_train_loader, ahead_valid_loader,
lr=0.05, n_epochs=2)output:
Epoch 1/2, train loss: 0.0693, train metric: 0.2941, valid metric: 0.1618
Epoch 2/2, train loss: 0.0207, train metric: 0.1647, valid metric: 0.1438
143809.52715873718LSTM (Long Short-Term Memory)
LSTM giải quyết vấn đề Vanishing Gradient bằng Cell State và 3 cổng (Forget, Input, Output).
class LstmModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.rnn = nn.LSTM(input_size, hidden_size, batch_first=True)
self.output = nn.Linear(hidden_size, output_size)
def forward(self, X):
outputs, last_state = self.rnn(X)
return self.output(outputs[:, -1])torch.manual_seed(42)
lstm_model = LstmModel(input_size=5, hidden_size=32, output_size=14)
lstm_model = lstm_model.to(device)
fit_and_evaluate(lstm_model, ahead_train_loader, ahead_valid_loader,
lr=0.05, n_epochs=2)output:
Epoch 1/2, train loss: 0.0940, train metric: 0.3618, valid metric: 0.2087
Epoch 2/2, train loss: 0.0258, train metric: 0.1747, valid metric: 0.1717
171688.33315372467Thực hành cài đặt thủ công LSTMCell (tùy chọn):
class LstmModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.hidden_size = hidden_size
# Sử dụng LSTMCell để tự cài đặt vòng lặp
self.memory_cell = nn.LSTMCell(input_size, hidden_size)
self.output = nn.Linear(hidden_size, output_size)
def forward(self, X):
batch_size, window_length, dimensionality = X.shape
X_time_first = X.transpose(0, 1)
H = torch.zeros(batch_size, self.hidden_size, device=X.device)
C = torch.zeros(batch_size, self.hidden_size, device=X.device)
for X_t in X_time_first:
H, C = self.memory_cell(X_t, (H, C))
return self.output(H)torch.manual_seed(42)
lstm_model = LstmModel(input_size=5, hidden_size=32, output_size=14)
lstm_model = lstm_model.to(device)
fit_and_evaluate(lstm_model, ahead_train_loader, ahead_valid_loader, lr=0.05, n_epochs=2)output:
Epoch 1/2, train loss: 0.0940, train metric: 0.3618, valid metric: 0.2087
Epoch 2/2, train loss: 0.0258, train metric: 0.1747, valid metric: 0.1717
171688.46726417542GRU (Gated Recurrent Unit)
GRU là phiên bản tối giản của LSTM, gộp 2 trạng thái thành 1 () và chỉ dùng 2 cổng (Update, Reset).
class GruModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.rnn = nn.GRU(input_size, hidden_size, batch_first=True)
self.output = nn.Linear(hidden_size, output_size)
def forward(self, X):
outputs, last_state = self.rnn(X)
return self.output(outputs[:, -1])torch.manual_seed(42)
gru_model = GruModel(input_size=5, hidden_size=32, output_size=14)
gru_model = gru_model.to(device)
fit_and_evaluate(gru_model, ahead_train_loader, ahead_valid_loader,
lr=0.05, n_epochs=2)output:
Epoch 1/2, train loss: 0.0813, train metric: 0.3289, valid metric: 0.1562
Epoch 2/2, train loss: 0.0212, train metric: 0.1757, valid metric: 0.1410
141032.75537490845Thực hành cài đặt thủ công GRUCell (tùy chọn):
class GruModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.hidden_size = hidden_size
self.memory_cell = nn.GRUCell(input_size, hidden_size)
self.output = nn.Linear(hidden_size, output_size)
def forward(self, X):
batch_size, window_length, dimensionality = X.shape
X_time_first = X.transpose(0, 1)
H = torch.zeros(batch_size, self.hidden_size, device=X.device)
for X_t in X_time_first:
H = self.memory_cell(X_t, H)
return self.output(H)torch.manual_seed(42)
gru_model = GruModel(input_size=5, hidden_size=32, output_size=14)
gru_model = gru_model.to(device)
fit_and_evaluate(gru_model, ahead_train_loader, ahead_valid_loader,
lr=0.05, n_epochs=2)output:
Epoch 1/2, train loss: 0.0813, train metric: 0.3289, valid metric: 0.1561
Epoch 2/2, train loss: 0.0212, train metric: 0.1757, valid metric: 0.1410
141033.3216190338Sử dụng Lớp Tích chập Một chiều (1D Conv) để Xử lý Chuỗi
Kết hợp Conv1D để giảm chiều (downsampling) trước khi đưa vào RNN giúp xử lý chuỗi dài hiệu quả hơn.
class DownsamplingModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
# Conv1d giảm kích thước chuỗi đi một nửa (stride=2)
self.conv = nn.Conv1d(input_size, hidden_size, kernel_size=4, stride=2)
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)
self.linear = nn.Linear(hidden_size, output_size)
def forward(self, X):
Z = X.permute(0, 2, 1) # Conv1d yêu cầu [Batch, Channel, Time]
Z = self.conv(Z)
Z = Z.permute(0, 2, 1) # Đổi lại cho GRU [Batch, Time, Features]
Z = torch.relu(Z)
Z, _states = self.gru(Z)
return self.linear(Z)
torch.manual_seed(42)
dseq_model = DownsamplingModel(input_size=1, hidden_size=32, output_size=14)
dseq_model = dseq_model.to(device)class DownsampledDataset(Seq2SeqDataset):
def __getitem__(self, idx):
window, target = super().__getitem__(idx)
# Cắt bỏ 3 phần tử đầu và lấy mẫu cách quãng (downsample) target để khớp với output của Conv1d
return window, target[3::2]
window_length = 112
dseq_train_set = DownsampledDataset(rail_train, window_length)
dseq_train_loader = DataLoader(dseq_train_set, batch_size=32, shuffle=True)
dseq_valid_set = DownsampledDataset(rail_valid, window_length)
dseq_valid_loader = DataLoader(dseq_valid_set, batch_size=32)
dseq_test_set = DownsampledDataset(rail_test, window_length)
dseq_test_loader = DataLoader(dseq_test_set, batch_size=32)torch.manual_seed(42)
dseq_model = DownsamplingModel(input_size=1, hidden_size=32, output_size=14)
dseq_model = dseq_model.to(device)
fit_and_evaluate(dseq_model, dseq_train_loader, dseq_valid_loader,
lr=0.2, n_epochs=2)output:
Epoch 1/2, train loss: 0.0595, train metric: 0.2736, valid metric: 0.1971
Epoch 2/2, train loss: 0.0204, train metric: 0.1694, valid metric: 0.1572
157235.7565164566WaveNet
Kiến trúc Fully Convolutional Network sử dụng Causal Dilated Convolutions.
import torch.nn.functional as F
class CausalConv1d(nn.Conv1d):
def forward(self, X):
# Tính toán padding dựa trên kernel_size và dilation
padding = (self.kernel_size[0] - 1) * self.dilation[0]
# Chỉ padding bên trái (quá khứ)
X = F.pad(X, (padding, 0))
return super().forward(X)class WavenetModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
layers = []
# Xây dựng các lớp với dilation tăng dần: 1, 2, 4, 8, ...
for dilation in (1, 2, 4, 8) * 2:
conv = CausalConv1d(input_size, hidden_size, kernel_size=2,
dilation=dilation)
layers += [conv, nn.ReLU()]
input_size = hidden_size
self.convs = nn.Sequential(*layers)
self.output = nn.Linear(hidden_size, output_size)
def forward(self, X):
Z = X.permute(0, 2, 1)
Z = self.convs(Z)
Z = Z.permute(0, 2, 1)
return self.output(Z)
torch.manual_seed(42)
wavenet_model = WavenetModel(input_size=5, hidden_size=32, output_size=14)
wavenet_model = wavenet_model.to(device)fit_and_evaluate(wavenet_model, seq_train_loader, seq_valid_loader,
lr=0.1, n_epochs=150)output:
Epoch 1/150, train loss: 0.0847, train metric: 0.3390, valid metric: 0.1920
...
Epoch 150/150, train loss: 0.0161, train metric: 0.1579, valid metric: 0.1468
140761.04760169983Ôn tập
- RNN: Mạng có trạng thái nội tại, phù hợp dữ liệu chuỗi. Huấn luyện khó do vanishing/exploding gradients.
- LSTM/GRU: Giải pháp cho vấn đề trí nhớ dài hạn (long-term dependency).
- 1D CNN & WaveNet: Xử lý song song tốt hơn RNN, sử dụng dilated convolution để mở rộng trường tiếp nhận (receptive field).
- Kỹ thuật dự báo:
- Univariate vs Multivariate.
- Single-step vs Multi-step (Direct vs Autoregressive vs Seq2Seq).
Thực hành 1: Dự báo cả Tàu điện và Xe buýt
class Seq2SeqRailBusDataset(torch.utils.data.Dataset):
def __init__(self, series, window_length, forecast_ahead):
self.series = series
self.window_length = window_length
self.forecast_ahead = forecast_ahead
def __len__(self):
return len(self.series) - self.window_length - self.forecast_ahead + 1
def __getitem__(self, idx):
if idx >= len(self):
raise IndexError("dataset index out of range")
end = idx + self.window_length
window = self.series[idx : end]
# Lấy cả 2 cột đầu tiên (rail, bus)
target_period = self.series[idx + 1 : end + self.forecast_ahead, :2]
target = target_period.unfold(dimension=0, size=self.forecast_ahead,
step=1)
return window, targetwindow_length = 56
forecast_ahead = 14
seq2seq_rb_train_set = Seq2SeqRailBusDataset(mulvar_train, window_length,
forecast_ahead)
seq2seq_rb_train_loader = DataLoader(seq2seq_rb_train_set, batch_size=32,
shuffle=True)
seq2seq_rb_valid_set = Seq2SeqRailBusDataset(mulvar_valid, window_length,
forecast_ahead)
seq2seq_rb_valid_loader = DataLoader(seq2seq_rb_valid_set, batch_size=32)
seq2seq_rb_test_set = Seq2SeqRailBusDataset(mulvar_test, window_length,
forecast_ahead)
seq2seq_rb_test_loader = DataLoader(seq2seq_rb_test_set, batch_size=32)class Seq2SeqRailBusModel(nn.Module):
def __init__(self, input_size, hidden_size, output_length, output_size):
super().__init__()
self.rnn = nn.LSTM(input_size, hidden_size, batch_first=True)
self.output = nn.Linear(hidden_size, output_length * output_size)
self.output_length = output_length
self.output_size = output_size
def forward(self, X):
B, L, _ = X.shape
outputs, last_state = self.rnn(X)
preds = self.output(outputs)
# Reshape thành [Batch, Time, Output_Size, Forecast_Len]
return preds.view(B, L, self.output_size, self.output_length)torch.manual_seed(42)
seq2seq_rb_model = Seq2SeqRailBusModel(input_size=5, hidden_size=32,
output_length=14, output_size=2)
seq2seq_rb_model = seq2seq_rb_model.to(device)
fit_and_evaluate(seq2seq_rb_model, seq2seq_rb_train_loader,
seq2seq_rb_valid_loader, lr=1.0, n_epochs=65,
patience=5, factor=0.5)output:
Epoch 1/65, train loss: 0.0532, train metric: 0.2550, valid metric: 0.1607
...
Epoch 65/65, train loss: 0.0029, train metric: 0.0447, valid metric: 0.0479
47059.00326371193seq2seq_rb_model.eval()
with torch.no_grad():
some_window = mulvar_valid[:window_length] # shape [56, 5]
X = some_window.unsqueeze(dim=0) # shape [1, 56, 5]
Y_preds = seq2seq_rb_model(X.to(device)) # shape [1, 56, 2, 14]
Y_pred = Y_preds[0, -1] # shape [2, 14] - Lấy dự báo tại bước cuốiY_pred_rail_s = pd.Series(Y_pred[0].cpu() * 1e6,
index=pd.date_range("2019-02-26", "2019-03-11"))
Y_pred_bus_s = pd.Series(Y_pred[1].cpu() * 1e6,
index=pd.date_range("2019-02-26", "2019-03-11"))
fig, ax = plt.subplots(figsize=(8, 3.5))
df["2019-02-01":"2019-03-11"]["rail"].plot(label="Rail", marker=".", ax=ax,
color="#ef8636", alpha=0.3)
df["2019-02-01":"2019-03-11"]["bus"].plot(label="Bus", marker=".", ax=ax,
color="#3b76af", alpha=0.3)
Y_pred_rail_s.plot(grid=True, marker=".", ax=ax, color="#ef8636",
label="Rail prediction")
Y_pred_bus_s.plot(grid=True, marker=".", ax=ax, color="#3b76af",
label="Bus prediction")
ax.vlines("2019-02-25", 0, 1e6, color="k", linestyle="--", label="Today")
ax.set_ylim([200_000, 850_000])
plt.legend(loc="center left")
plt.show()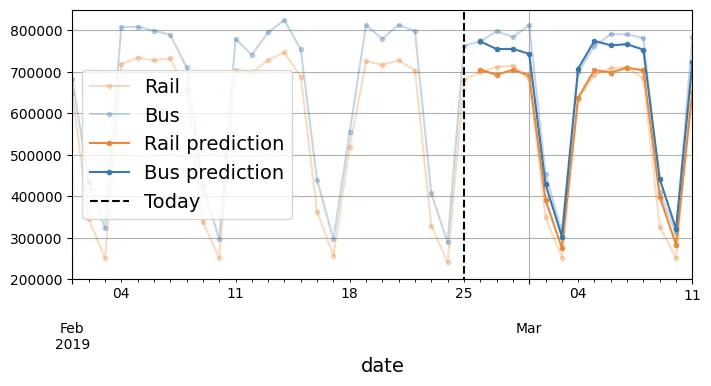
Thực hành 2: Tạo nhạc Bach Chorales
from pathlib import Path
import tarfile
import urllib.request
def download_bach_chorales():
bach_chorales_dir = Path("datasets/jsb_chorales")
if not bach_chorales_dir.exists():
tarball_path = Path("datasets/jsb_chorales.tgz")
if not tarball_path.exists():
Path("datasets").mkdir(parents=True, exist_ok=True)
print("Downloading...", end="")
urllib.request.urlretrieve("https://homl.info/bach", tarball_path)
print("Done.")
with tarfile.open(tarball_path) as housing_tarball:
print("Decompressing...", end="")
housing_tarball.extractall(path="datasets", filter="data")
print("Done.")
return bach_chorales_dir
bach_chorales_dir = download_bach_chorales()output:
Downloading...Done.
Decompressing...Done.print(Path(bach_chorales_dir / "train" / "chorale_000.csv").read_text()[:84] + "...")output:
note0,note1,note2,note3
74,70,65,58
74,70,65,58
74,70,65,58
74,70,65,58
75,70,58,55
...import csv
def load_chorales(bach_chorales_dir):
chorales = {"train": [], "valid": [], "test": []}
for subset, chorale_list in chorales.items():
for chorale_path in sorted((bach_chorales_dir / subset).glob("*.csv")):
with chorale_path.open() as f:
reader = csv.reader(f)
next(reader) # bỏ qua header
chorale = [[int(note) for note in row] for row in reader]
chorale_list.append(torch.tensor(chorale))
return chorales
chorales = load_chorales(bach_chorales_dir)chorales["train"][0][:5]output:
tensor([[74, 70, 65, 58],
[74, 70, 65, 58],
[74, 70, 65, 58],
[74, 70, 65, 58],
[75, 70, 58, 55]])Các hàm xử lý âm thanh:
from IPython.display import Audio
# (Các hàm notes_to_frequencies, frequencies_to_samples, chords_to_samples, play_chords)
# ... [giữ nguyên code gốc]Chuẩn bị dữ liệu cho mô hình sinh nhạc:
import torch.nn.functional as F
def preprocess_note_indices(note_indices, length=None):
notes_one_hot = F.one_hot(note_indices, num_classes=48).to(torch.float32)
if length is None:
length = len(note_indices)
idx = torch.arange(len(note_indices), dtype=torch.float32,
device=note_indices.device).view(-1, 1) - 1
return torch.cat([
notes_one_hot,
idx % 4, # Chỉ số nốt trong hợp âm (0-3)
idx % 16 // 4, # Chỉ số hợp âm trong nhịp (0-3)
idx / (length - 1)# Tiến độ
], dim=-1)
class BachDataset(torch.utils.data.Dataset):
def __init__(self, chorales, window_length):
self.chorales = chorales
self.windows = []
sos = torch.tensor([1])
for chorale in chorales:
notes = chorale.view(-1)
note_indices = torch.cat([sos, F.relu(notes - 34)])
X = preprocess_note_indices(note_indices)
for index in range(len(notes) - window_length):
self.windows.append((
X[index : index + window_length],
note_indices[index + 1 : index + window_length + 1]
))
def __len__(self):
return len(self.windows)
def __getitem__(self, index):
return self.windows[index]
window_length = 128
train_set = BachDataset(chorales["train"], window_length)
valid_set = BachDataset(chorales["valid"], window_length)
test_set = BachDataset(chorales["test"], window_length)X, y = train_set[0]
X.shape, y.shapeoutput:
(torch.Size([128, 51]), torch.Size([128]))torch.manual_seed(42)
batch_size = 32
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
valid_loader = DataLoader(valid_set, batch_size=batch_size)
test_loader = DataLoader(test_set, batch_size=batch_size)Mô hình BachModel kết hợp Causal Conv1d và LSTM:
class BachModel(nn.Module):
def __init__(self, n_inputs=51, conv_dim=32, lstm_dim=64, n_notes=48):
super().__init__()
conv_layers = []
# Stack 4 lớp Causal Conv với dilation tăng dần
for idx in range(4):
conv_layers += [
CausalConv1d(n_inputs, conv_dim, kernel_size=2, dilation=2**idx),
nn.ReLU(),
nn.BatchNorm1d(conv_dim),
]
n_inputs = conv_dim
self.conv_stack = nn.Sequential(*conv_layers)
self.lstm = nn.LSTM(input_size=conv_dim, hidden_size=lstm_dim, batch_first=True)
self.output = nn.Linear(lstm_dim, n_notes)
def forward(self, X):
Z = X.transpose(1, 2) # [B, T, F] -> [B, F, T] cho Conv1d
Z = self.conv_stack(Z)
Z = Z.transpose(1, 2) # [B, F, T] -> [B, T, F] cho LSTM
Z, _ = self.lstm(Z)
Z = self.output(Z)
return Z.transpose(1, 2) # Trả về [B, N_notes, T] cho CrossEntropyLoss
torch.manual_seed(42)
bach_model = BachModel().to(device)torch.manual_seed(42)
optimizer = torch.optim.NAdam(bach_model.parameters(), lr=1e-4)
criterion = nn.CrossEntropyLoss()
accuracy = torchmetrics.Accuracy(task="multiclass", num_classes=48).to(device)
history = train(bach_model, optimizer, criterion, accuracy, train_loader,
valid_loader, n_epochs=5)output:
Epoch 1/5, train loss: 1.1150, train metric: 0.7214, valid metric: 0.8175
...
Epoch 5/5, train loss: 0.4773, train metric: 0.8547, valid metric: 0.8324evaluate_tm(bach_model, test_loader, accuracy)output:
tensor(0.8251, device='cuda:0')Hàm sinh nhạc:
def generate_chorale_v2(model, seed_chords, num_chords, temperature=1):
target_length = num_chords * 4 + 1
notes = seed_chords.to(device).view(-1)
sos = torch.tensor([1], dtype=torch.long, device=device)
note_indices = torch.cat([sos, F.relu(notes - 34)])
while len(note_indices) < target_length:
X = preprocess_note_indices(note_indices, target_length)
with torch.no_grad():
new_note_logits = model(X.unsqueeze(0))
# Áp dụng temperature scaling
new_note_probas = F.softmax(new_note_logits[0, :, -1] / temperature, dim=0)
# Lấy mẫu ngẫu nhiên dựa trên phân phối xác suất
new_note_index = torch.multinomial(new_note_probas, num_samples=1)
note_indices = torch.cat([note_indices, new_note_index])
print(f"\r{len(note_indices) / target_length:.1%}", end="")
notes = note_indices.where(note_indices < 2, note_indices + 34)
return notes[1:].reshape(-1, 4)seed_chords = chorales["valid"][1][:8]
generated_chorales = {}
for temperature in (0.6, 1.0, 1.1):
torch.manual_seed(42)
print("Temperature:", temperature)
chorale = generate_chorale_v2(bach_model, seed_chords, 52, temperature).cpu()
generated_chorales[temperature] = chorale
play_chords(chorale)import soundfile as sf
def save_chorale(filepath, chords, tempo=160, amplitude=0.1, sample_rate=44100):
samples = amplitude * chords_to_samples(chords, tempo, sample_rate)
sf.write(filepath, samples, sample_rate)
save_chorale("my_chorale.mp3", generated_chorales[0.6])