[DL101] Chương 11: Reinforcement Learning (Học Tăng Cường)
Giới thiệu về Reinforcement Learning, Q-Learning và Deep Q-Networks (DQN)
Bài viết có tham khảo, sử dụng và sửa đổi tài nguyên từ kho lưu trữ handson-mlp, tuân thủ giấy phép Apache‑2.0. Chúng tôi chân thành cảm ơn tác giả Aurélien Géron (@aureliengeron) vì sự chia sẻ kiến thức tuyệt vời và những đóng góp quý giá cho cộng đồng.
Chào mừng bạn đến với chương về Reinforcement Learning (Học tăng cường - RL). Khác với học có giám sát (Supervised Learning) nơi mô hình học từ dữ liệu đã được dán nhãn, hay học không giám sát (Unsupervised Learning) nơi mô hình tìm kiếm cấu trúc ẩn trong dữ liệu, Học tăng cường là quá trình một Agent (Tác nhân) học cách ra quyết định thông qua việc thử và sai (trial-and-error) khi tương tác với một Environment (Môi trường).
Trong chương này, chúng ta sẽ đi từ những khái niệm như Policy (Chính sách), Markov Decision Process (Quy trình quyết định Markov) đến các thuật toán hiện đại như Deep Q-Networks (DQN) và PPO.
Bạn có thể chạy trực tiếp các đoạn mã code tại: Google Colab.
1. Cài đặt môi trường
Trước khi đi vào lý thuyết và thực hành, chúng ta cần thiết lập môi trường làm việc. Dự án này yêu cầu Python phiên bản 3.10 trở lên để đảm bảo tính tương thích của các thư viện.
import sys
# Kiểm tra phiên bản Python, yêu cầu >= 3.10
assert sys.version_info >= (3, 10)Chúng ta cần xác định xem code đang chạy trên môi trường Google Colab hay Kaggle để cài đặt các thư viện phụ trợ phù hợp.
IS_COLAB = "google.colab" in sys.modules
IS_KAGGLE = "kaggle_secrets" in sys.modulesCài đặt các thư viện phụ thuộc:
Nếu sử dụng Colab, thư viện Box2D (dùng cho vật lý mô phỏng) và Stable-Baselines3 (thư viện RL mạnh mẽ) chưa được cài đặt sẵn. Trên Kaggle, dù đã có sẵn nhưng phiên bản thường cũ, do đó chúng ta cần cập nhật.
- Gymnasium: Là phiên bản kế thừa và được duy trì tích cực của thư viện
gymnổi tiếng từ OpenAI, cung cấp giao diện chuẩn cho các môi trường RL. - Box2D: Thư viện vật lý 2D dùng cho các môi trường như
LunarLanderhayBipedalWalker. - Stable-Baselines3: Cung cấp các thuật toán RL chuẩn mực (SOTA) được cài đặt sẵn.
if IS_COLAB:
%pip uninstall -qy gym
%pip install -qU Box2D stable_baselines3
if IS_KAGGLE:
%pip uninstall -qy gym
%pip install -qU gymnasium
%pip install -qU Box2D stable_baselines3output:
[?25l [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [32m0.0/3.7 MB [0m [31m? [0m eta [36m-:--:-- [0m
[2K [91m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [91m╸ [0m [32m3.7/3.7 MB [0m [31m220.1 MB/s [0m eta [36m0:00:01 [0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [32m3.7/3.7 MB [0m [31m101.4 MB/s [0m eta [36m0:00:00 [0m
[?25h [?25l [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [32m0.0/188.0 kB [0m [31m? [0m eta [36m-:--:-- [0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [0m [32m188.0/188.0 kB [0m [31m18.4 MB/s [0m eta [36m0:00:00 [0m
[?25hChúng ta cũng cần PyTorch phiên bản mới nhất (>= 2.6.0) để xây dựng các mạng nơ-ron.
from packaging.version import Version
import torch
assert Version(torch.__version__) >= Version("2.6.0")Cấu hình phần cứng:
Các thuật toán RL, đặc biệt là Deep RL, tiêu tốn rất nhiều tài nguyên tính toán. Việc sử dụng GPU (hoặc MPS trên Mac) sẽ tăng tốc độ huấn luyện lên đáng kể so với CPU.
if torch.cuda.is_available():
device = "cuda"
elif torch.backends.mps.is_available():
device = "mps"
else:
device = "cpu"
deviceoutput:
'cuda'Cảnh báo nếu không tìm thấy bộ tăng tốc phần cứng:
if device == "cpu":
print("Mạng nơ-ron có thể chạy rất chậm nếu không có phần cứng tăng tốc.")
if IS_COLAB:
print("Vui lòng vào Runtime > Change runtime type và chọn GPU.")
if IS_KAGGLE:
print("Vui lòng vào Settings > Accelerator và chọn GPU.")Thiết lập hiển thị biểu đồ và hoạt hình (animation) với matplotlib. Chúng ta sẽ sử dụng Javascript HTML (jshtml) để hiển thị các chuyển động của Agent ngay trong notebook.
import matplotlib.animation
import matplotlib.pyplot as plt
plt.rc('font', size=14)
plt.rc('axes', labelsize=14, titlesize=14)
plt.rc('legend', fontsize=14)
plt.rc('xtick', labelsize=10)
plt.rc('ytick', labelsize=10)
plt.rc('animation', html='jshtml')Cuối cùng, tải extension tensorboard để theo dõi quá trình huấn luyện sau này.
%load_ext tensorboard2. Giới thiệu về Gymnasium
Gymnasium (trước đây là OpenAI Gym) là một bộ công cụ tiêu chuẩn để phát triển và so sánh các thuật toán RL. Nó cung cấp các môi trường mô phỏng (như Atari, Box2D, Robotics) với một giao diện lập trình (API) thống nhất.
Chúng ta sẽ bắt đầu với môi trường kinh điển: CartPole-v1.
- Mục tiêu: Giữ thăng bằng một cây gậy (pole) gắn trên một chiếc xe đẩy (cart).
- Trạng thái (State/Observation): Vị trí xe, vận tốc xe, góc nghiêng của gậy, vận tốc góc của gậy.
- Hành động (Action): Đẩy xe sang trái (0) hoặc sang phải (1).
import gymnasium as gym
# Tạo môi trường CartPole-v1, chế độ render là rgb_array để lấy ảnh
env = gym.make("CartPole-v1", render_mode="rgb_array", max_episode_steps=1000)# Code phụ - hiển thị danh sách 5 môi trường đầu tiên có sẵn
envs = gym.envs.registry
sorted(envs.keys())[:5] + ["..."]output:
['Acrobot-v1', 'Ant-v2', 'Ant-v3', 'Ant-v4', 'Ant-v5', '...']# Code phụ - xem thông số kỹ thuật của môi trường CartPole-v1
envs["CartPole-v1"]output:
EnvSpec(id='CartPole-v1', entry_point='gymnasium.envs.classic_control.cartpole:CartPoleEnv', reward_threshold=475.0, nondeterministic=False, max_episode_steps=500, order_enforce=True, disable_env_checker=False, kwargs={}, namespace=None, name='CartPole', version=1, additional_wrappers=(), vector_entry_point='gymnasium.envs.classic_control.cartpole:CartPoleVectorEnv')# Hiển thị toàn bộ registry (danh sách các môi trường)
gym.pprint_registry()output:
===== classic_control =====
Acrobot-v1 CartPole-v0 CartPole-v1
MountainCar-v0 MountainCarContinuous-v0 Pendulum-v1
===== phys2d =====
phys2d/CartPole-v0 phys2d/CartPole-v1 phys2d/Pendulum-v0
===== box2d =====
BipedalWalker-v3 BipedalWalkerHardcore-v3 CarRacing-v3
LunarLander-v3 LunarLanderContinuous-v3
===== toy_text =====
Blackjack-v1 CliffWalking-v1 CliffWalkingSlippery-v1
FrozenLake-v1 FrozenLake8x8-v1 Taxi-v3
===== tabular =====
tabular/Blackjack-v0 tabular/CliffWalking-v0
===== None =====
Ant-v2 Ant-v3 GymV21Environment-v0
GymV26Environment-v0 HalfCheetah-v2 HalfCheetah-v3
Hopper-v2 Hopper-v3 Humanoid-v2
Humanoid-v3 HumanoidStandup-v2 InvertedDoublePendulum-v2
InvertedPendulum-v2 Pusher-v2 Reacher-v2
Swimmer-v2 Swimmer-v3 Walker2d-v2
Walker2d-v3
===== mujoco =====
Ant-v4 Ant-v5 HalfCheetah-v4
HalfCheetah-v5 Hopper-v4 Hopper-v5
Humanoid-v4 Humanoid-v5 HumanoidStandup-v4
HumanoidStandup-v5 InvertedDoublePendulum-v4 InvertedDoublePendulum-v5
InvertedPendulum-v4 InvertedPendulum-v5 Pusher-v4
Pusher-v5 Reacher-v4 Reacher-v5
Swimmer-v4 Swimmer-v5 Walker2d-v4
Walker2d-v5Khởi tạo môi trường:
Hàm reset() đưa môi trường về trạng thái ban đầu và trả về quan sát (observation) đầu tiên cùng với thông tin bổ sung.
obs, info = env.reset(seed=42)
obs
# Kết quả obs là một mảng 4 giá trị: [vị trí xe, vận tốc xe, góc gậy, vận tốc góc]output:
array([ 0.0273956 , -0.00611216, 0.03585979, 0.0197368 ], dtype=float32)info # Thông tin phụ (thường trống trong CartPole)output:
{}Hiển thị môi trường:
Hàm render() trả về hình ảnh của môi trường (nếu render_mode='rgb_array').
img = env.render()
img.shape # chiều cao, chiều rộng, số kênh màu (3 = Red, Green, Blue)output:
(400, 600, 3)# Code phụ - hàm để vẽ môi trường bằng matplotlib
def plot_environment(env, figsize=(5, 4)):
plt.figure(figsize=figsize)
img = env.render()
plt.imshow(img)
plt.axis("off")
return img
plot_environment(env)
plt.show()
Không gian hành động (Action Space):
Discrete(2) nghĩa là có 2 hành động rời rạc có thể thực hiện: 0 (trái) và 1 (phải).
env.action_spaceoutput:
Discrete(2)Tương tác với môi trường (Step):
Hàm step(action) thực hiện hành động và trả về 5 giá trị:
obs: Trạng thái mới.reward: Phần thưởng nhận được.done: Boolean,Truenếu tập chơi kết thúc (gậy đổ hoặc xe ra khỏi màn hình).truncated: Boolean,Truenếu tập chơi bị ngắt do giới hạn thời gian.info: Thông tin bổ sung.
action = 1 # Đẩy xe sang phải
obs, reward, done, truncated, info = env.step(action)
obsoutput:
array([ 0.02727336, 0.18847767, 0.03625453, -0.26141977], dtype=float32)reward, done, truncated, infooutput:
(1.0, False, False, {})Nếu môi trường đã kết thúc (done hoặc truncated), ta phải gọi reset() để bắt đầu lại.
if done or truncated:
obs, info = env.reset()3. Chính sách đơn giản (Simple Hard-coded Policy)
Policy (Chính sách), ký hiệu là , là hàm quyết định hành động mà Agent sẽ thực hiện tại trạng thái .
Dưới đây là một chính sách “cứng” (hard-coded) đơn giản: Nếu gậy nghiêng sang trái (góc < 0), đẩy xe sang trái. Ngược lại, đẩy sang phải.
def basic_policy(obs):
angle = obs[2] # obs[2] là góc nghiêng của gậy
return 0 if angle < 0 else 1 # Sang trái nếu nghiêng trái, ngược lại sang phải
totals = []
# Chạy thử nghiệm 500 tập (episodes)
for episode in range(500):
total_rewards = 0
obs, info = env.reset(seed=episode)
while True:
action = basic_policy(obs)
obs, reward, done, truncated, info = env.step(action)
total_rewards += reward
if done or truncated:
break
totals.append(total_rewards)Hãy xem hiệu quả của chính sách đơn giản này thông qua các thống kê:
import numpy as np
# Tính trung bình, độ lệch chuẩn, min, max của phần thưởng
np.mean(totals), np.std(totals), min(totals), max(totals)output:
(np.float64(41.698), np.float64(8.389445512070509), 24.0, 63.0)Kết quả cho thấy chính sách này không thực sự tốt. Để trực quan hơn, chúng ta sẽ tạo một đoạn phim (animation) của một tập chơi.
# Code phụ - hàm hiển thị animation của một tập chơi
def update_scene(num, frames, patch):
patch.set_data(frames[num])
return patch,
def plot_animation(frames, repeat=False, interval=40):
fig = plt.figure()
patch = plt.imshow(frames[0])
plt.axis('off')
anim = matplotlib.animation.FuncAnimation(
fig, update_scene, fargs=(frames, patch),
frames=len(frames), repeat=repeat, interval=interval)
plt.close()
return anim
def show_one_episode(policy, seed=42):
frames = []
env = gym.make("CartPole-v1", render_mode="rgb_array",
max_episode_steps=1000)
obs, info = env.reset(seed=seed)
while True:
frames.append(env.render())
action = policy(obs)
obs, reward, done, truncated, info = env.step(action)
if done or truncated:
break
env.close()
return plot_animation(frames)
show_one_episode(basic_policy)<form title="Repetition mode" aria-label="Repetition mode" action="#n" name="_anim_loop_selectac01449c684246108842453e05cd932b"
class="anim-state">
<input type="radio" name="state" value="once" id="_anim_radio1_ac01449c684246108842453e05cd932b"
checked>
<label for="_anim_radio1_ac01449c684246108842453e05cd932b">Once</label>
<input type="radio" name="state" value="loop" id="_anim_radio2_ac01449c684246108842453e05cd932b"
>
<label for="_anim_radio2_ac01449c684246108842453e05cd932b">Loop</label>
<input type="radio" name="state" value="reflect" id="_anim_radio3_ac01449c684246108842453e05cd932b"
>
<label for="_anim_radio3_ac01449c684246108842453e05cd932b">Reflect</label>
</form>Như bạn thấy, hệ thống rất không ổn định và gậy bị đổ chỉ sau vài lần lắc lư. Chúng ta cần một cách tiếp cận thông minh hơn: Sử dụng Mạng nơ-ron.
4. Chính sách dựa trên Mạng Nơ-ron (Neural Network Policies)
Thay vì dùng quy tắc cứng (if angle < 0), ta dùng một mạng nơ-ron để nhận đầu vào là trạng thái (observations) và đầu ra là xác suất của từng hành động. Chính sách này gọi là Stochastic Policy (Chính sách ngẫu nhiên).
Mô hình nhận đầu vào là vector 4 chiều (trạng thái), đi qua một lớp ẩn, và đầu ra là 1 giá trị xác suất (xác suất chọn hành động di chuyển sang trái - hoặc phải tùy quy ước). Ở đây ta dùng lớp Linear cuối cùng xuất ra 1 giá trị, sau đó dùng hàm Sigmoid (ẩn trong phân phối Bernoulli) để biến nó thành xác suất .
import torch
import torch.nn as nn
class PolicyNetwork(nn.Module):
def __init__(self):
super().__init__()
# Mạng đơn giản: Input(4) -> Linear(5) -> ReLU -> Linear(1)
self.net = nn.Sequential(nn.Linear(4, 5), nn.ReLU(), nn.Linear(5, 1))
def forward(self, state):
return self.net(state)Chọn hành động:
Ta sử dụng phân phối Bernoulli. Mạng nơ-ron trả về logit (giá trị chưa qua hàm kích hoạt xác suất). torch.distributions.Bernoulli(logits=logit) sẽ tự động áp dụng hàm Sigmoid lên logit để có xác suất , và sau đó lấy mẫu hành động (0 hoặc 1) dựa trên .
Hàm này cũng trả về log_prob (logarit của xác suất hành động vừa chọn), giá trị này cực kỳ quan trọng để tính toán đạo hàm trong quá trình huấn luyện sau này.
def choose_action(model, obs):
state = torch.as_tensor(obs)
logit = model(state)
dist = torch.distributions.Bernoulli(logits=logit)
action = dist.sample()
log_prob = dist.log_prob(action)
return int(action.item()), log_probHãy xem mạng nơ-ron chưa được huấn luyện (trọng số ngẫu nhiên) hoạt động như thế nào.
# Code phụ - hiển thị animation với mạng nơ-ron
torch.manual_seed(42)
model = PolicyNetwork()
model.eval()
def neural_net_policy(obs):
with torch.no_grad():
action, _ = choose_action(model, obs)
return action
show_one_episode(neural_net_policy)<form title="Repetition mode" aria-label="Repetition mode" action="#n" name="_anim_loop_selecte58c12a640bb4930aa510f6207e93508"
class="anim-state">
<input type="radio" name="state" value="once" id="_anim_radio1_e58c12a640bb4930aa510f6207e93508"
checked>
<label for="_anim_radio1_e58c12a640bb4930aa510f6207e93508">Once</label>
<input type="radio" name="state" value="loop" id="_anim_radio2_e58c12a640bb4930aa510f6207e93508"
>
<label for="_anim_radio2_e58c12a640bb4930aa510f6207e93508">Loop</label>
<input type="radio" name="state" value="reflect" id="_anim_radio3_e58c12a640bb4930aa510f6207e93508"
>
<label for="_anim_radio3_e58c12a640bb4930aa510f6207e93508">Reflect</label>
</form>Tất nhiên, do chưa được huấn luyện nên kết quả vẫn là thất bại. Bây giờ chúng ta sẽ tìm cách huấn luyện nó.
5. Policy Gradients (Gradient Chính sách)
Ý tưởng cốt lõi của Policy Gradients là tối ưu hóa trực tiếp các tham số của mạng nơ-ron để tối đa hóa tổng phần thưởng mong đợi.
Hàm mục tiêu (Objective function) là tổng phần thưởng kỳ vọng. Gradient của hàm mục tiêu theo tham số được tính xấp xỉ bằng:
Trong đó:
- là xác suất chọn hành động tại trạng thái .
- là Return (Tổng phần thưởng tích lũy) từ thời điểm đến cuối tập chơi.
Thuật toán REINFORCE
Một vấn đề quan trọng là Credit Assignment Problem (Bài toán gán tín dụng): Khi nhận phần thưởng ở cuối game, hành động nào trong quá khứ đã đóng góp vào kết quả đó? Để giải quyết, ta sử dụng Discount Factor (Hệ số chiết khấu) (gamma).
Tổng phần thưởng chiết khấu được tính như sau:
Ví dụ: Nếu phần thưởng là [10, 0, -50] và :
- Hành động 3 nhận:
- Hành động 2 nhận:
- Hành động 1 nhận:
def compute_returns(rewards, discount_factor):
returns = rewards[:] # copy danh sách rewards
# Tính ngược từ cuối lên đầu
for step in range(len(returns) - 1, 0, -1):
returns[step - 1] += returns[step] * discount_factor
return torch.tensor(returns)compute_returns([10, 0, -50], discount_factor=0.8)output:
tensor([-22., -40., -50.])Hàm run_episode sẽ chạy một tập chơi hoàn chỉnh và lưu lại log_prob (để tính đạo hàm) và rewards (để tính ).
def run_episode(model, env, seed=None):
log_probs, rewards = [], []
obs, info = env.reset(seed=seed)
while True:
action, log_prob = choose_action(model, obs)
obs, reward, done, truncated, _info = env.step(action)
log_probs.append(log_prob)
rewards.append(reward)
if done or truncated:
return log_probs, rewardsHuấn luyện với REINFORCE:
Quy trình:
- Chạy một episode, thu thập
log_probsvàrewards. - Tính returns đã chiết khấu.
- Chuẩn hóa returns (trừ trung bình, chia độ lệch chuẩn) để ổn định quá trình học.
- Tính Loss: . Dấu trừ vì ta muốn dùng Gradient Descent để tối thiểu hóa Loss (tương đương tối đa hóa Reward).
- Cập nhật trọng số mạng nơ-ron.
def train_reinforce(model, optimizer, env, n_episodes, discount_factor):
for episode in range(n_episodes):
seed = torch.randint(0, 2**32, size=()).item()
log_probs, rewards = run_episode(model, env, seed=seed)
returns = compute_returns(rewards, discount_factor)
# Chuẩn hóa returns
std_returns = (returns - returns.mean()) / (returns.std() + 1e-7)
# Tính loss cho từng bước và cộng lại
losses = [-logp * rt for logp, rt in zip(log_probs, std_returns)]
loss = torch.cat(losses).sum()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"\rEpisode {episode + 1}, Reward: {sum(rewards):.2f}", end=" ")Tiến hành huấn luyện trong 200 tập:
torch.manual_seed(42)
model = PolicyNetwork()
optimizer = torch.optim.NAdam(model.parameters(), lr=0.06)
train_reinforce(model, optimizer, env, n_episodes=200, discount_factor=0.95)output:
Episode 200, Reward: 1000.00 Sau khi huấn luyện, hãy xem kết quả:
show_one_episode(neural_net_policy)Output hidden; open in https://colab.research.google.com to view.6. Kiến thức bổ sung: Markov Chains (Chuỗi Markov)
Trước khi đến với Q-Learning, hãy hiểu về nền tảng lý thuyết của nó: Markov Chain. Một chuỗi Markov bao gồm tập hợp các trạng thái và xác suất chuyển đổi giữa chúng. Tính chất Markov (Markov Property) phát biểu rằng: “Tương lai chỉ phụ thuộc vào hiện tại, không phụ thuộc vào quá khứ”.
Dưới đây mô phỏng một chuỗi Markov với ma trận xác suất chuyển đổi:
np.random.seed(42)
transition_probabilities = [ # shape=[s, s'] (từ dòng s đến cột s')
[0.7, 0.2, 0.0, 0.1], # từ s0 đến s0, s1, s2, s3
[0.0, 0.0, 0.9, 0.1], # từ s1 đến s0, s1, s2, s3
[0.0, 1.0, 0.0, 0.0], # từ s2 đến s0, s1, s2, s3
[0.0, 0.0, 0.0, 1.0]] # từ s3 đến s0, s1, s2, s3 (trạng thái kết thúc)
n_max_steps = 1000 # giới hạn số bước tránh lặp vô tận
terminal_states = [3]
def run_chain(start_state):
current_state = start_state
for step in range(n_max_steps):
print(current_state, end=" ")
if current_state in terminal_states:
break
current_state = np.random.choice(
range(len(transition_probabilities)),
p=transition_probabilities[current_state]
)
else:
print("...", end="")
print()
for idx in range(10):
print(f"Run #{idx + 1}: ", end="")
run_chain(start_state=0)output:
Run #1: 0 0 3
Run #2: 0 1 2 1 2 1 2 1 2 1 3
Run #3: 0 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 3
Run #4: 0 3
Run #5: 0 1 2 1 2 1 2 1 2 1 2 1 2 1 3
Run #6: 0 1 3
Run #7: 0 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 3
Run #8: 0 0 0 1 2 1 2 1 3
Run #9: 0 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 3
Run #10: 0 0 0 1 2 1 3 7. Markov Decision Process (MDP - Quy trình Quyết định Markov)
MDP mở rộng chuỗi Markov bằng cách thêm vào:
- Hành động (Actions - A): Agent có thể chọn hành động để tác động lên xác suất chuyển trạng thái.
- Phần thưởng (Rewards - R): Agent nhận được phần thưởng sau mỗi bước chuyển.
Một MDP được định nghĩa bởi bộ 4: .
- : Xác suất chuyển từ sang khi thực hiện .
- : Phần thưởng nhận được khi chuyển từ sang qua .
# Định nghĩa MDP ví dụ:
# transition_probabilities[s][a][s']
transition_probabilities = [
[[0.7, 0.3, 0.0], [1.0, 0.0, 0.0], [0.8, 0.2, 0.0]], # Từ s0
[[0.0, 1.0, 0.0], None, [0.0, 0.0, 1.0]], # Từ s1
[None, [0.8, 0.1, 0.1], None] # Từ s2
]
# rewards[s][a][s']
rewards = [
[[+10, 0, 0], [0, 0, 0], [0, 0, 0]],
[[0, 0, 0], [0, 0, 0], [0, 0, -50]],
[[0, 0, 0], [+40, 0, 0], [0, 0, 0]]
]
possible_actions = [[0, 1, 2], [0, 2], [1]] # Các hành động khả thi tại mỗi trạng thái8. Q-Value Iteration (Lặp giá trị Q)
Mục tiêu của chúng ta là tìm Q-Value : Tổng phần thưởng chiết khấu tối đa mà Agent có thể nhận được nếu bắt đầu tại trạng thái , thực hiện hành động , và sau đó chơi tối ưu.
Công thức Bellman Optimality Equation cho Q-value:
Thuật toán này lặp đi lặp lại việc cập nhật bảng Q-values cho đến khi hội tụ.
Q_values = np.full((3, 3), -np.inf) # -vô cùng cho các hành động không thể thực hiện
for state, actions in enumerate(possible_actions):
Q_values[state, actions] = 0.0 # Khởi tạo giá trị 0.0 cho hành động khả thigamma = 0.90 # Hệ số chiết khấu
history1 = [] # Lưu lịch sử để vẽ biểu đồ
for iteration in range(50):
Q_prev = Q_values.copy()
history1.append(Q_prev)
for s in range(3):
for a in possible_actions[s]:
# Áp dụng công thức Bellman
Q_values[s, a] = np.sum([
transition_probabilities[s][a][sp]
* (rewards[s][a][sp] + gamma * Q_prev[sp].max())
for sp in range(3)])
history1 = np.array(history1)Q_valuesoutput:
array([[18.91891892, 17.02702702, 13.62162162],
[ 0. , -inf, -4.87971488],
[ -inf, 50.13365013, -inf]])Sau khi có bảng Q-values, chính sách tối ưu đơn giản là chọn hành động có Q-value cao nhất tại mỗi trạng thái (Greedy Policy).
Q_values.argmax(axis=1) # Hành động tối ưu cho mỗi trạng tháioutput:
array([0, 0, 1])Với , chính sách tối ưu là: Tại s0 chọn a0, s1 chọn a0, s2 chọn a1. Nếu bạn tăng lên 0.95 (coi trọng tương lai hơn), hành động tại s1 có thể thay đổi để chấp nhận rủi ro ngắn hạn nhằm đạt phần thưởng lớn dài hạn.
9. Q-Learning
Trong thực tế, ta thường không biết trước xác suất chuyển và phần thưởng . Q-Learning cho phép Agent học Q-values trực tiếp thông qua trải nghiệm thực tế (Sampling) mà không cần mô hình môi trường.
Công thức cập nhật Q-Learning:
Trong đó là Learning Rate (Tốc độ học).
# Hàm mô phỏng môi trường (do ta không có môi trường thực ở đây)
def step(state, action):
probas = transition_probabilities[state][action]
next_state = np.random.choice([0, 1, 2], p=probas)
reward = rewards[state][action][next_state]
return next_state, rewardTa cần một chính sách khám phá (Exploration Policy) để đảm bảo Agent đi qua đủ mọi trạng thái. Ở đây ta dùng ngẫu nhiên.
def exploration_policy(state):
return np.random.choice(possible_actions[state])Tiến hành chạy Q-Learning:
np.random.seed(42)
Q_values = np.full((3, 3), -np.inf)
for state, actions in enumerate(possible_actions):
Q_values[state][actions] = 0alpha0 = 0.05 # Tốc độ học khởi tạo
decay = 0.005 # Hệ số giảm tốc độ học
gamma = 0.90 # Hệ số chiết khấu
state = 0 # Trạng thái bắt đầu
history2 = []
for iteration in range(10_000):
history2.append(Q_values.copy())
action = exploration_policy(state)
next_state, reward = step(state, action)
next_value = Q_values[next_state].max() # Chính sách tham lam (Greedy) cho bước kế tiếp
alpha = alpha0 / (1 + iteration * decay) # Giảm dần alpha
# Cập nhật Q-value
Q_values[state, action] *= 1 - alpha
Q_values[state, action] += alpha * (reward + gamma * next_value)
state = next_state
history2 = np.array(history2)So sánh tốc độ hội tụ của Q-Value Iteration (lý thuyết) và Q-Learning (thực nghiệm):
# Code phụ - vẽ biểu đồ so sánh
true_Q_value = history1[-1, 0, 0]
fig, axes = plt.subplots(1, 2, figsize=(10, 4), sharey=True)
axes[0].set_ylabel("Q-value$(s_0, a_0)$", fontsize=14)
axes[0].set_title("Q-value iteration", fontsize=14)
axes[1].set_title("Q-learning", fontsize=14)
for ax, width, history in zip(axes, (50, 10000), (history1, history2)):
ax.plot([0, width], [true_Q_value, true_Q_value], "k--")
ax.plot(np.arange(width), history[:, 0, 0], "b-", linewidth=2)
ax.set_xlabel("Iterations", fontsize=14)
ax.axis([0, width, 0, 24])
ax.grid(True)
plt.show()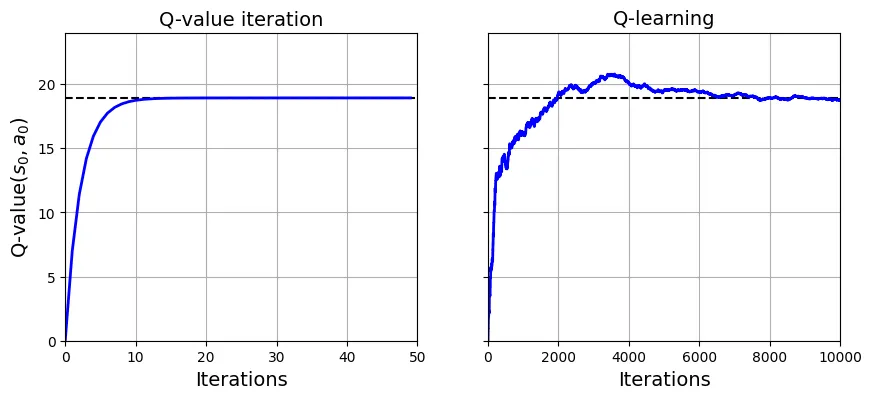
10. Deep Q-Network (DQN)
Với các bài toán phức tạp (như CartPole hay Atari), không gian trạng thái quá lớn để lưu trong bảng Q (Table). Giải pháp là dùng một Mạng nơ-ron để xấp xỉ hàm Q: . Đây chính là Deep Q-Network (DQN).
Mạng DQN nhận đầu vào là trạng thái (4 chiều) và đầu ra là giá trị Q cho mỗi hành động (2 chiều).
class DQN(nn.Module):
def __init__(self):
super().__init__()
# Mạng 3 lớp ẩn
self.net = nn.Sequential(nn.Linear(4, 32), nn.ReLU(),
nn.Linear(32, 32), nn.ReLU(),
nn.Linear(32, 2))
def forward(self, state):
return self.net(state)Epsilon-Greedy Policy: Để cân bằng giữa khám phá (Exploration) và khai thác (Exploitation), ta dùng chiến lược -greedy: Với xác suất , chọn hành động ngẫu nhiên; ngược lại chọn hành động có Q-value cao nhất.
def choose_dqn_action(model, obs, epsilon=0.0):
if torch.rand(()) < epsilon: # epsilon-greedy: khám phá
return torch.randint(2, size=()).item()
else: # khai thác
state = torch.as_tensor(obs)
Q_values = model(state)
return Q_values.argmax().item() # chọn hành động tốt nhất theo dự đoánReplay Buffer (Bộ đệm phát lại): RL truyền thống học trên các mẫu liên tiếp (Correlated data), điều này rất tệ cho mạng nơ-ron. Replay Buffer lưu trữ các trải nghiệm và lấy mẫu ngẫu nhiên (batch) để huấn luyện, giúp phá vỡ sự tương quan thời gian và ổn định quá trình học.
def sample_experiences(replay_buffer, batch_size):
# Lấy ngẫu nhiên các chỉ số
indices = torch.randint(len(replay_buffer), size=[batch_size])
batch = [replay_buffer[index] for index in indices.tolist()]
# Chuyển đổi thành tensor cho từng thành phần
return [to_tensor([exp[index] for exp in batch]) for index in range(6)]
def to_tensor(data):
array = np.stack(data)
dtype = torch.float32 if array.dtype == np.float64 else None
return torch.as_tensor(array, dtype=dtype)Dưới đây là một cài đặt đơn giản của Replay Buffer sử dụng danh sách vòng tròn (circular buffer) để tối ưu bộ nhớ.
class ReplayBuffer:
def __init__(self, max_length):
self.data = [None] * max_length
self.max_length = max_length
self.index = 0
self.length = 0
def append(self, obj):
self.data[self.index] = obj
self.length = min(self.length + 1, self.max_length)
self.index = (self.index + 1) % self.max_length
def __getitem__(self, index):
if index < 0 or index >= self.length:
raise IndexError(f"replay buffer index out of range: {index}")
return self.data[index]
def __len__(self):
return self.length
buff = ReplayBuffer(max_length=4)
for i in range(8):
buff.append(i)
print(f"Length: {len(buff)}, data: {buff.data}")output:
Length: 1, data: [0, None, None, None]
Length: 2, data: [0, 1, None, None]
Length: 3, data: [0, 1, 2, None]
Length: 4, data: [0, 1, 2, 3]
Length: 4, data: [4, 1, 2, 3]
Length: 4, data: [4, 5, 2, 3]
Length: 4, data: [4, 5, 6, 3]
Length: 4, data: [4, 5, 6, 7]Hàm chơi một tập và lưu trải nghiệm vào bộ đệm:
def play_and_record_episode(model, env, replay_buffer, epsilon, seed=None):
obs, _info = env.reset(seed=seed)
total_rewards = 0
model.eval()
with torch.no_grad():
while True:
action = choose_dqn_action(model, obs, epsilon)
next_obs, reward, done, truncated, _info = env.step(action)
# Lưu trải nghiệm: (s, a, r, s', done, truncated)
experience = (obs, action, reward, next_obs, done, truncated)
replay_buffer.append(experience)
total_rewards += reward
if done or truncated:
return total_rewards
obs = next_obsBước huấn luyện DQN:
Ta cần tính Loss giữa:
- Q-Value dự đoán: từ mạng hiện tại.
- Target Q-Value: .
Lưu ý: Để ổn định, người ta thường dùng một Target Network riêng biệt để tính giá trị mục tiêu , nhưng ở ví dụ đơn giản này ta dùng chính mạng model (điều này có thể gây mất ổn định nhưng đủ cho CartPole).
def dqn_training_step(model, optimizer, criterion, replay_buffer, batch_size,
discount_factor):
experiences = sample_experiences(replay_buffer, batch_size)
state, action, reward, next_state, done, truncated = experiences
# Tính Target Q-Value
with torch.no_grad():
next_Q_value = model(next_state)
max_next_Q_value, _ = next_Q_value.max(dim=1)
# Nếu done/truncated thì không cộng phần tương lai
running = (~(done | truncated)).float()
target_Q_value = reward + running * discount_factor * max_next_Q_value
# Tính Q-Value hiện tại
all_Q_values = model(state)
Q_value = all_Q_values.gather(dim=1, index=action.unsqueeze(1))
# Tính Loss (thường là MSE hoặc Huber Loss)
loss = criterion(Q_value, target_Q_value.unsqueeze(1))
optimizer.zero_grad()
loss.backward()
optimizer.step()Bắt đầu quy trình huấn luyện DQN:
from collections import deque
def train_dqn(model, env, replay_buffer, optimizer, criterion, n_episodes=800,
warmup=30, batch_size=32, discount_factor=0.95):
totals = []
for episode in range(n_episodes):
# Giảm dần epsilon từ 1.0 xuống 0.01
epsilon = max(1 - episode / 500, 0.01)
seed = torch.randint(0, 2**32, size=()).item()
# Chơi và thu thập dữ liệu
total_rewards = play_and_record_episode(model, env, replay_buffer,
epsilon, seed=seed)
print(f"\rEpisode: {episode + 1}, Rewards: {total_rewards}", end=" ")
totals.append(total_rewards)
# Chỉ bắt đầu train khi buffer đã có đủ dữ liệu (warmup)
if episode >= warmup:
dqn_training_step(model, optimizer, criterion, replay_buffer,
batch_size, discount_factor)
return totals
torch.manual_seed(42)
dqn = DQN()
optimizer = torch.optim.NAdam(dqn.parameters(), lr=0.03)
mse = nn.MSELoss()
replay_buffer = deque(maxlen=100_000) # Sử dụng deque làm buffer
totals = train_dqn(dqn, env, replay_buffer, optimizer, mse)output:
Episode: 800, Rewards: 1000.0 Vẽ biểu đồ quá trình học:
plt.figure(figsize=(8, 4))
plt.plot(totals)
plt.xlabel("Episode", fontsize=14)
plt.ylabel("Sum of rewards", fontsize=14)
plt.grid(True)
plt.show()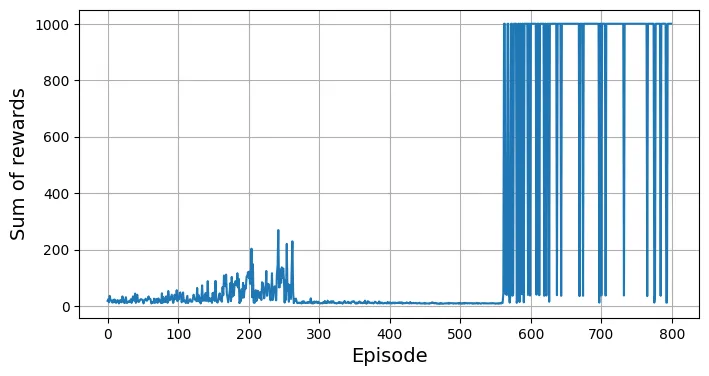
Xem kết quả DQN:
torch.manual_seed(42)
dqn.eval()
def dqn_policy(obs):
with torch.no_grad():
return choose_dqn_action(dqn, obs)
show_one_episode(dqn_policy)Output hidden; open in https://colab.research.google.com to view.Một chiếc CartPole cực kỳ ổn định! 😀
11. Actor-Critic
Phương pháp Actor-Critic kết hợp ưu điểm của Policy Gradient (Actor) và Value-based (Critic).
- Actor (Diễn viên): Học chính sách để ra quyết định.
- Critic (Nhà phê bình): Học hàm giá trị để đánh giá xem trạng thái hiện tại tốt hay xấu.
Thay vì đợi hết episode để tính Return (như REINFORCE), Actor-Critic dùng Critic để ước lượng phần thưởng tương lai ngay lập tức, giảm phương sai (variance) của Gradient.
class ActorCritic(nn.Module):
def __init__(self):
super().__init__()
# Phần thân chung (Feature Extractor)
self.body = nn.Sequential(nn.Linear(4, 32), nn.ReLU(),
nn.Linear(32, 32), nn.ReLU())
# Actor head: xuất ra logits cho hành động
self.actor_head = nn.Linear(32, 1)
# Critic head: xuất ra giá trị ước lượng của trạng thái (Value function)
self.critic_head = nn.Linear(32, 1)
def forward(self, state):
features = self.body(state)
return self.actor_head(features), self.critic_head(features)def choose_action_and_evaluate(model, obs):
state = torch.as_tensor(obs)
logit, state_value = model(state)
dist = torch.distributions.Bernoulli(logits=logit)
action = dist.sample()
log_prob = dist.log_prob(action)
return int(action.item()), log_prob, state_valueHàm Loss của Actor-Critic: Trong đó đóng vai trò như lợi thế (Advantage).
def ac_training_step(optimizer, criterion, state_value, target_value, log_prob,
critic_weight):
td_error = target_value - state_value
# Loss cho Actor: thay vì nhân với Gt, ta nhân với TD_Error
# detach() để không truyền đạo hàm ngược qua Critic head khi tính Actor loss
actor_loss = -log_prob * td_error.detach()
# Loss cho Critic: MSE giữa dự đoán và thực tế
critic_loss = criterion(state_value, target_value)
# Tổng hợp loss
loss = actor_loss + critic_weight * critic_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()def get_target_value(model, next_obs, reward, done, truncated, discount_factor):
with torch.inference_mode():
_, _, next_state_value = choose_action_and_evaluate(model, next_obs)
running = 0.0 if (done or truncated) else 1.0
target_value = reward + running * discount_factor * next_state_value
return target_valueHuấn luyện Actor-Critic diễn ra theo từng bước (step-by-step), không cần đợi hết tập.
def run_episode_and_train(model, optimizer, criterion, env, discount_factor,
critic_weight, seed=None):
obs, _info = env.reset(seed=seed)
total_rewards = 0
while True:
action, log_prob, state_value = choose_action_and_evaluate(model, obs)
next_obs, reward, done, truncated, _info = env.step(action)
target_value = get_target_value(model, next_obs, reward, done,
truncated, discount_factor)
# Huấn luyện ngay sau mỗi bước
ac_training_step(optimizer, criterion, state_value, target_value,
log_prob, critic_weight)
total_rewards += reward
if done or truncated:
return total_rewards
obs = next_obsdef train_actor_critic(model, optimizer, criterion, env, n_episodes=400,
discount_factor=0.95, critic_weight=0.3):
totals = []
model.train()
for episode in range(n_episodes):
seed = torch.randint(0, 2**32, size=()).item()
total_rewards = run_episode_and_train(model, optimizer, criterion, env,
discount_factor, critic_weight,
seed=seed)
totals.append(total_rewards)
print(f"\rEpisode: {episode + 1}, Rewards: {total_rewards}", end=" ")
return totalstorch.manual_seed(42)
ac_model = ActorCritic()
optimizer = torch.optim.NAdam(ac_model.parameters(), lr=1.1e-3)
criterion = nn.MSELoss()
totals = train_actor_critic(ac_model, optimizer, criterion, env)output:
Episode: 400, Rewards: 18.0 Xem kết quả của Actor-Critic:
torch.manual_seed(42)
ac_model.eval()
def actor_critic_policy(obs):
with torch.no_grad():
action, _, _ = choose_action_and_evaluate(ac_model, obs)
return action
show_one_episode(actor_critic_policy)Output hidden; open in https://colab.research.google.com to view.# Vẽ biểu đồ huấn luyện Actor-Critic
plt.figure(figsize=(8, 4))
plt.plot(totals)
plt.xlabel("Episode", fontsize=14)
plt.ylabel("Sum of rewards", fontsize=14)
plt.grid(True)
plt.show()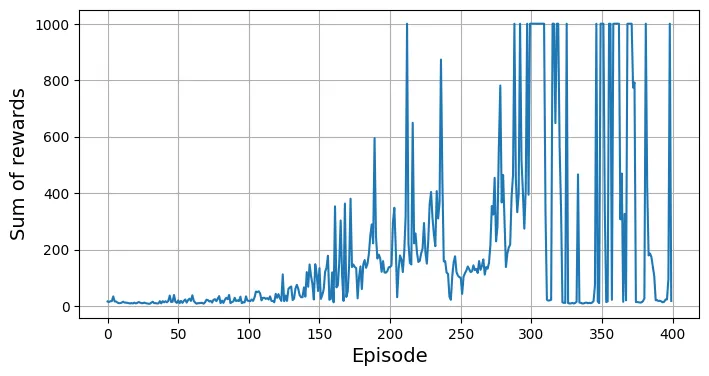
12. PPO (Proximal Policy Optimization)
PPO hiện nay được coi là thuật toán RL mặc định (default) vì tính ổn định và hiệu quả của nó. PPO giải quyết vấn đề của Policy Gradient: nếu bước cập nhật quá lớn, chính sách có thể bị hỏng hoàn toàn và khó phục hồi.
PPO giới hạn sự thay đổi của chính sách bằng cách sử dụng hàm mục tiêu “cắt ngọn” (clipped objective function), đảm bảo chính sách mới không đi quá xa so với chính sách cũ.
Ở đây chúng ta sẽ sử dụng thư viện stable-baselines3, một thư viện tối ưu hóa cao cho các thuật toán này.
import ale_py
ale = ale_py.ALEInterface()Nếu bạn chạy trên máy cá nhân và dùng Anaconda, bạn cần cài đặt ROMs cho Atari thủ công:
gymnasium_atari_was_installed_using_anaconda = False
if gymnasium_atari_was_installed_using_anaconda:
%pip install -qU AutoROM
from pathlib import Path
from AutoROM import main as autorom
autorom(accept_license=True, source_file=None, # Chấp nhận license Atari
install_dir=Path(ale_py.roms.__path__[0]), quiet=False)Chúng ta sẽ huấn luyện trên môi trường Breakout của Atari. Stable-baselines3 cung cấp hàm make_atari_env để tự động tiền xử lý ảnh (cắt, giảm kích thước, chuyển sang đen trắng) và gộp nhiều môi trường chạy song song.
from stable_baselines3.common.env_util import make_atari_env
# Tạo 4 môi trường chạy song song để tăng tốc độ thu thập dữ liệu
envs = make_atari_env("BreakoutNoFrameskip-v4", n_envs=4, seed=42)
obs = envs.reset() # trả về mảng shape (4, 84, 84, 1)obs.shapeoutput:
(4, 84, 84, 1)Hãy xem sự khác biệt giữa ảnh gốc và ảnh sau khi tiền xử lý:
plt.figure(figsize=(9, 4))
plt.subplot(1, 2, 1)
plt.title("Original 210 ✕ 160 RGB")
plt.imshow(envs.get_images()[0])
plt.axis("off")
plt.subplot(1, 2, 2)
plt.title("Preprocessed 84 ✕ 84 Grayscale")
plt.imshow(obs[0, :, :, 0], cmap="gray")
plt.axis("off")
plt.show()
Frame Stacking: Vì ảnh tĩnh không thể hiện được vận tốc của quả bóng, ta chồng 4 frame liên tiếp lên nhau thành một quan sát duy nhất.
from stable_baselines3.common.vec_env import VecFrameStack
envs_stacked = VecFrameStack(envs, n_stack=4)
obs = envs_stacked.reset() # trả về mảng shape (4, 84, 84, 4)Khởi tạo mô hình PPO:
Chúng ta sử dụng CnnPolicy vì đầu vào là hình ảnh (cần mạng Convolutional Neural Network).
from stable_baselines3 import PPO
tensorboard_logdir = "my_ppo_breakout_tensorboard" # thư mục log
ppo_model = PPO("CnnPolicy", envs_stacked, device=device, learning_rate=2.5e-4,
batch_size=256, n_steps=256, n_epochs=4, clip_range=0.1,
vf_coef=0.5, ent_coef=0.01, gamma=0.99, verbose=0,
tensorboard_log=tensorboard_logdir)ppo_model.policy # Xem kiến trúc mạngoutput:
ActorCriticCnnPolicy(
(features_extractor): NatureCNN(
(cnn): Sequential(
(0): Conv2d(4, 32, kernel_size=(8, 8), stride=(4, 4))
(1): ReLU()
(2): Conv2d(32, 64, kernel_size=(4, 4), stride=(2, 2))
(3): ReLU()
(4): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
(5): ReLU()
(6): Flatten(start_dim=1, end_dim=-1)
)
(linear): Sequential(
(0): Linear(in_features=3136, out_features=512, bias=True)
(1): ReLU()
)
)
...
)Khởi động TensorBoard để theo dõi:
%tensorboard --logdir={tensorboard_logdir} --port 6006Output hidden; open in https://colab.research.google.com to view.Bắt đầu huấn luyện:
Quá trình này có thể mất vài giờ tùy vào phần cứng. Ta dùng CheckpointCallback để lưu mô hình định kỳ.
from stable_baselines3.common.callbacks import CheckpointCallback
cb = CheckpointCallback(save_freq=100_000, save_path="my_checkpoints",
name_prefix="breakout")
# Train 200,000 bước (thực tế cần hàng triệu bước để chơi giỏi)
ppo_model.learn(total_timesteps=200_000, progress_bar=True, callback=cb)
ppo_model.save("my_ppo_agent_breakout") # lưu mô hình cuối cùngoutput:
Output()Để tiết kiệm thời gian, bạn có thể tải một mô hình đã được huấn luyện sẵn (30 triệu bước).
import urllib.request
data_root = "https://raw.githubusercontent.com/ageron/data/refs/heads/main"
filename = "ppo_agent_breakout.zip"
urllib.request.urlretrieve(f"{data_root}/{filename}", f"my_{filename}")output:
('my_ppo_agent_breakout.zip', <http.client.HTTPMessage at 0x7e7eb0957080>)Kiểm thử mô hình:
ppo_model = PPO.load("my_ppo_agent_breakout") # tải checkpoint tốt nhất
eval_env = make_atari_env("BreakoutNoFrameskip-v4", n_envs=1, seed=42)
eval_stacked = VecFrameStack(eval_env, n_stack=4)
frames = []
obs = eval_stacked.reset()
for _ in range(5000): # Giới hạn số bước
frames.append(eval_stacked.render())
action, _ = ppo_model.predict(obs, deterministic=True) # deterministic=True để tái lập kết quả
obs, reward, done, info = eval_stacked.step(action)
if done[0]: # xong game
break
eval_stacked.close()plot_animation(frames)<form title="Repetition mode" aria-label="Repetition mode" action="#n" name="_anim_loop_select0443fa0956b542c9a6a854bb427192fa"
class="anim-state">
<input type="radio" name="state" value="once" id="_anim_radio1_0443fa0956b542c9a6a854bb427192fa"
checked>
<label for="_anim_radio1_0443fa0956b542c9a6a854bb427192fa">Once</label>
<input type="radio" name="state" value="loop" id="_anim_radio2_0443fa0956b542c9a6a854bb427192fa"
>
<label for="_anim_radio2_0443fa0956b542c9a6a854bb427192fa">Loop</label>
<input type="radio" name="state" value="reflect" id="_anim_radio3_0443fa0956b542c9a6a854bb427192fa"
>
<label for="_anim_radio3_0443fa0956b542c9a6a854bb427192fa">Reflect</label>
</form>Bạn cũng có thể thử với các game khác như Centipede bằng cách thay đổi tên môi trường.
Hy vọng bạn đã có cái nhìn tổng quan và sâu sắc về Học Tăng Cường thông qua chương này!
Ôn tập
1. Học tăng cường là gì?
Học tăng cường (Reinforcement Learning - RL) là một lĩnh vực của Machine Learning nhằm xây dựng các tác nhân (agents) có khả năng ra quyết định hành động trong một môi trường để tối đa hóa phần thưởng tích lũy theo thời gian.
Khác biệt:
- So với Supervised Learning: RL không có “đáp án đúng” (label) cho từng input. Nó học qua thử-sai và tín hiệu phần thưởng thường bị trễ (delayed).
- So với Unsupervised Learning: RL có mục tiêu rõ ràng (tối đa hóa phần thưởng) thay vì chỉ tìm cấu trúc ẩn của dữ liệu. RL cũng yêu cầu sự tương tác liên tục với môi trường.
2. Ba ứng dụng thực tế của RL
- Cá nhân hóa âm nhạc:
- Môi trường: Web radio của người dùng.
- Tác nhân: Phần mềm đề xuất bài hát.
- Hành động: Chọn bài hát hoặc quảng cáo để phát.
- Phần thưởng: + điểm khi nghe hết bài, ++ điểm khi click quảng cáo, - điểm khi tắt hoặc skip.
- Marketing:
- Môi trường: Hồ sơ khách hàng và lịch sử mua hàng.
- Tác nhân: Hệ thống gửi email/khuyến mãi.
- Hành động: Gửi hoặc không gửi email.
- Phần thưởng: Doanh thu từ chiến dịch (-) chi phí gửi.
- Giao hàng tự động:
- Môi trường: Mạng lưới giao thông.
- Tác nhân: Đội xe tải.
- Hành động: Chọn lộ trình, điểm dừng.
- Phần thưởng: + điểm khi giao đúng giờ, - điểm khi trễ hoặc tốn nhiên liệu.
3. Hệ số chiết khấu (Discount Factor) là gì?
Hệ số chiết khấu (gamma) là một tham số (thường từ 0 đến 1) dùng để định giá phần thưởng trong tương lai so với hiện tại. càng gần 0, tác nhân càng “cận thị” (chỉ quan tâm phần thưởng ngay lập tức). càng gần 1, tác nhân càng biết lo xa. Thay đổi chắc chắn thay đổi chính sách tối ưu. Ví dụ: Nếu thấp, tác nhân sẽ chọn ăn 1 quả táo ngay lập tức thay vì đợi 10 phút để được 2 quả táo.
4. Đo lường hiệu suất RL?
Hiệu suất thường được đo bằng tổng phần thưởng tích lũy (Total Cumulative Reward) trên mỗi tập chơi (episode). Trong nghiên cứu, ta thường vẽ biểu đồ “Learning Curve”: trục tung là phần thưởng trung bình, trục hoành là số bước huấn luyện.
5. Vấn đề gán tín dụng (Credit Assignment Problem)
Đây là vấn đề xác định xem hành động nào trong quá khứ thực sự chịu trách nhiệm cho phần thưởng (hoặc hình phạt) hiện tại. Nó xảy ra khi phần thưởng bị trễ (ví dụ: đi sai một nước cờ đầu game nhưng cuối game mới thua). Cách giảm thiểu: dùng hệ số chiết khấu, hoặc thiết kế phần thưởng phụ (reward shaping) chi tiết hơn.
6. Tại sao cần Replay Buffer?
Replay Buffer giúp phá vỡ sự tương quan (correlation) giữa các mẫu dữ liệu liên tiếp, giúp quá trình huấn luyện giống với i.i.d (independent and identically distributed) hơn, từ đó giúp mạng nơ-ron hội tụ ổn định hơn.
7. Off-policy là gì?
Thuật toán Off-policy (như Q-Learning, DQN) có thể học giá trị của chính sách tối ưu trong khi tác nhân lại hành động theo một chính sách khác (thường là chính sách khám phá). Lợi ích: Có thể học từ dữ liệu cũ (của chính nó hoặc tác nhân khác), tận dụng Replay Buffer hiệu quả.