[DL101] Chương 1: Giới thiệu về Mạng Nơ-ron Nhân tạo (Artificial Neural Networks)
Khái niệm cơ bản về Mạng Nơ-ron Nhân tạo, Perceptron và MLP
Bài viết có tham khảo, sử dụng và sửa đổi tài nguyên từ kho lưu trữ handson-mlp, tuân thủ giấy phép Apache‑2.0. Chúng tôi chân thành cảm ơn tác giả Aurélien Géron (@aureliengeron) vì sự chia sẻ kiến thức tuyệt vời và những đóng góp quý giá cho cộng đồng.
Mạng nơ-ron nhân tạo (Artificial Neural Networks - ANNs) là trọng tâm của Học sâu (Deep Learning). Về mặt toán học, chúng là các hàm xấp xỉ vạn năng (universal approximators), có khả năng biểu diễn các mối quan hệ phi tuyến phức tạp giữa không gian đầu vào (input space) và không gian đầu ra (output space). Mặc dù lấy cảm hứng từ cấu trúc sinh học của não bộ, sức mạnh của ANNs hiện đại nằm ở sự kết hợp giữa Đại số tuyến tính, Giải tích ma trận và Lý thuyết xác suất. Nhờ khả năng mở rộng cao, ANNs đã trở thành công cụ không thể thiếu trong các bài toán thị giác máy tính, xử lý ngôn ngữ tự nhiên và nhiều lĩnh vực khác.
Trong chương này, chúng ta sẽ bắt đầu tìm hiểu từ mô hình tuyến tính cơ bản nhất là Perceptron, sau đó tổng quát hóa lên kiến trúc Multi-Layer Perceptron (MLP) và nghiên cứu thuật toán Lan truyền ngược (Backpropagation) thông qua thư viện Scikit-Learn.
Bạn có thể chạy trực tiếp các đoạn mã code tại: Google Colab.
Thiết lập môi trường (Setup)
Các thư viện như Scikit-Learn liên tục cập nhật các thuật toán tối ưu hóa (solvers) và API. Việc kiểm soát phiên bản giúp đảm bảo các tham số mặc định và hành vi của mô hình thống nhất với nội dung thực hành.
Dự án này yêu cầu Python phiên bản 3.10 hoặc cao hơn:
import sys
# Kiểm tra phiên bản Python, nếu nhỏ hơn 3.10 sẽ báo lỗi
assert sys.version_info >= (3, 10)Đồng thời, chúng ta cũng cần thư viện Scikit-Learn phiên bản từ 1.6.1 trở lên:
from packaging.version import Version
import sklearn
# Đảm bảo Scikit-Learn >= 1.6.1
assert Version(sklearn.__version__) >= Version("1.6.1")Như thường lệ, chúng ta sẽ thiết lập kích thước phông chữ mặc định cho thư viện matplotlib để các biểu đồ hiển thị rõ ràng và thẩm mỹ hơn:
import matplotlib.pyplot as plt
# Thiết lập kích thước phông chữ cho các thành phần biểu đồ
plt.rc('font', size=14)
plt.rc('axes', labelsize=14, titlesize=14)
plt.rc('legend', fontsize=14)
plt.rc('xtick', labelsize=10)
plt.rc('ytick', labelsize=10)1. Từ Nơ-ron Sinh học đến Nơ-ron Nhân tạo
Perceptron: Kiến trúc mạng nơ-ron đơn giản nhất
Perceptron, được Frank Rosenblatt phát minh năm 1957, là nền tảng của các mạng nơ-ron hiện đại. Về bản chất toán học, Perceptron là một bộ phân loại nhị phân tuyến tính (linear binary classifier). Nó sử dụng Đơn vị Ngưỡng Tuyến tính (Threshold Logic Unit - TLU).
Cơ chế hoạt động của TLU có thể được mô tả qua công thức toán học sau: Cho vector đầu vào và vector trọng số tương ứng , cùng với một hệ số chệch (bias) . TLU tính tổng có trọng số :
Sau đó, một hàm kích hoạt dạng bước (step function) được áp dụng:
Quy tắc huấn luyện Perceptron (Perceptron Learning Rule) dựa trên việc cập nhật trọng số khi có sai số dự đoán, theo công thức: Trong đó:
- là trọng số thứ tại bước .
- là tốc độ học (learning rate).
- là nhãn thực tế, là nhãn dự đoán.
Dưới đây là cách huấn luyện một Perceptron đơn giản trên bộ dữ liệu hoa Iris bằng Scikit-Learn.
import numpy as np
from sklearn.datasets import load_iris
from sklearn.linear_model import Perceptron
# Tải bộ dữ liệu Iris
iris = load_iris(as_frame=True)
# Lấy hai đặc trưng: chiều dài cánh hoa (petal length) và chiều rộng cánh hoa (petal width)
X = iris.data[["petal length (cm)", "petal width (cm)"]].values
# Tạo nhãn mục tiêu: True nếu là Iris setosa (target == 0), ngược lại là False
y = (iris.target == 0)
# Khởi tạo và huấn luyện mô hình Perceptron
per_clf = Perceptron(random_state=42)
per_clf.fit(X, y)
# Dự đoán cho hai mẫu hoa mới
X_new = [[2, 0.5], [3, 1]]
y_pred = per_clf.predict(X_new) # Dự đoán True (Setosa) hoặc False (Không phải Setosa)Giải thích Code:
X: Chúng ta chỉ chọn 2 đặc trưng để dễ dàng trực quan hóa trên không gian 2 chiều (2D).y: Bài toán được đưa về dạng phân loại nhị phân (Binary Classification): Setosa (Lớp 1) và Non-Setosa (Lớp 0).Perceptron(random_state=42):random_stateđược cố định để đảm bảo việc khởi tạo trọng số ngẫu nhiên ban đầu là giống nhau mỗi lần chạy, giúp kết quả có tính tái lập.
y_predoutput:
array([ True, False])Phân tích Output:
Mô hình dự đoán mẫu đầu tiên [2, 0.5] là True (Iris Setosa) và mẫu thứ hai [3, 1] là False (không phải Iris Setosa). Điều này hợp lý vì Iris Setosa thường có cánh hoa nhỏ hơn. Về mặt hình học, điểm dữ liệu [2, 0.5] nằm về phía “dương” của siêu phẳng quyết định, trong khi [3, 1] nằm về phía “âm”.
Mối quan hệ giữa Perceptron và SGDClassifier
Trong Scikit-Learn, Perceptron thực chất là một trường hợp đặc biệt của SGDClassifier (Stochastic Gradient Descent Classifier). Điều này nhấn mạnh rằng bản chất của việc huấn luyện Perceptron là tối ưu hóa hàm mất mát (loss function).
Hàm mất mát của Perceptron là biến thể của Hinge Loss, được định nghĩa là: (với ). Nó sẽ phạt các điểm bị phân loại sai, và đạo hàm của hàm này dẫn đến chính quy tắc cập nhật trọng số đã nêu ở trên.
# Mã bổ sung - so sánh Perceptron và SGDClassifier
from sklearn.linear_model import SGDClassifier
# Cấu hình SGDClassifier để mô phỏng Perceptron
sgd_clf = SGDClassifier(loss="perceptron", penalty=None,
learning_rate="constant", eta0=1, random_state=42)
sgd_clf.fit(X, y)
# Kiểm tra xem các hệ số trọng số và hệ số chệch (bias) có giống nhau không
assert (sgd_clf.coef_ == per_clf.coef_).all()
assert (sgd_clf.intercept_ == per_clf.intercept_).all()Giải thích Code:
loss="perceptron": Chỉ định hàm mất mát cụ thể của Perceptron.penalty=None: Không áp dụng Regularization (như L1 hay L2), vì Perceptron cổ điển không có thành phần này.learning_rate="constant", eta0=1: Perceptron cổ điển không giảm tốc độ học theo thời gian; nó giữ nguyên bước nhảy .
Ranh giới quyết định (Decision Boundary)
Một đặc điểm quan trọng (và cũng là giới hạn) của Perceptron là nó chỉ giải quyết được các bài toán phân tách tuyến tính (linearly separable). Theo định lý hội tụ Perceptron, nếu dữ liệu phân tách tuyến tính, thuật toán đảm bảo tìm ra một nghiệm trong số hữu hạn bước. Ngược lại, nó sẽ dao động mãi mãi (nếu không giảm tốc độ học).
Phương trình đường ranh giới quyết định là nơi : Đây chính là phương trình đường thẳng mà chúng ta thấy trong đoạn code dưới đây.
# Mã bổ sung - vẽ ranh giới quyết định của Perceptron trên dữ liệu iris
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
# Tính toán hệ số đường thẳng ranh giới: w1*x1 + w2*x2 + b = 0 => x2 = -(w1/w2)*x1 - (b/w2)
a = -per_clf.coef_[0, 0] / per_clf.coef_[0, 1]
b = -per_clf.intercept_ / per_clf.coef_[0, 1]
axes = [0, 5, 0, 2]
# Tạo lưới điểm để vẽ nền màu
x0, x1 = np.meshgrid(
np.linspace(axes[0], axes[1], 500).reshape(-1, 1),
np.linspace(axes[2], axes[3], 200).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = per_clf.predict(X_new)
zz = y_predict.reshape(x0.shape)
custom_cmap = ListedColormap(['#9898ff', '#fafab0'])
plt.figure(figsize=(7, 3))
# Vẽ các điểm dữ liệu
plt.plot(X[y == 0, 0], X[y == 0, 1], "bs", label="Not Iris setosa")
plt.plot(X[y == 1, 0], X[y == 1, 1], "yo", label="Iris setosa")
# Vẽ đường ranh giới quyết định
plt.plot([axes[0], axes[1]], [a * axes[0] + b, a * axes[1] + b], "k-", linewidth=3)
# Tô màu vùng dự đoán
plt.contourf(x0, x1, zz, cmap=custom_cmap)
plt.xlabel("Chiều dài cánh hoa")
plt.ylabel("Chiều rộng cánh hoa")
plt.legend(loc="lower right")
plt.axis(axes)
plt.show()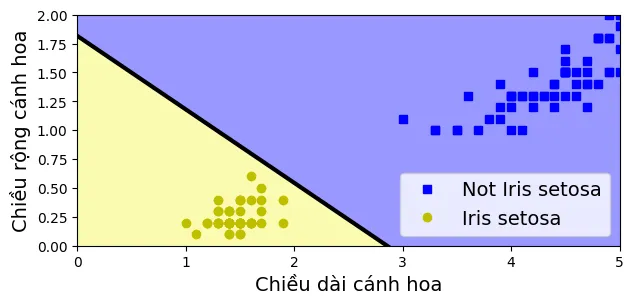
(Lưu ý: Hình ảnh minh họa output thực tế từ code, đường màu đen phân chia rõ ràng hai lớp dữ liệu).
Hàm kích hoạt (Activation Functions)
Tại sao chúng ta cần hàm kích hoạt phi tuyến? Nếu một mạng nơ-ron gồm nhiều lớp () nhưng chỉ sử dụng hàm kích hoạt tuyến tính , thì tổng hợp của chúng thực chất chỉ là một phép biến đổi tuyến tính duy nhất: . Mạng sâu sẽ bị “sụp đổ” về một mạng đơn lớp. Tính phi tuyến (non-linearity) cho phép mạng học được các biên quyết định phức tạp hơn, uốn lượn theo dữ liệu.
Dưới đây là biểu diễn toán học của các hàm kích hoạt phổ biến:
- Hàm Heaviside (Step): nếu , nếu . (Không khả vi tại 0, đạo hàm bằng 0 ở mọi nơi khác -> không dùng được cho Gradient Descent).
- ReLU (Rectified Linear Unit): Đạo hàm là 1 khi và 0 khi . ReLU giúp giảm thiểu vấn đề biến mất gradient (vanishing gradient) vì gradient không bị bão hòa (saturated) ở miền dương.
- Sigmoid (Logistic): Đạo hàm: . Giá trị bị ép vào khoảng .
- Tanh (Hyperbolic Tangent): Đạo hàm: . Giá trị trong khoảng , có tâm tại 0, giúp hội tụ nhanh hơn Sigmoid trong một số trường hợp.
# Mã bổ sung - tạo Hình vẽ: Các hàm kích hoạt và đạo hàm của chúng
from scipy.special import expit as sigmoid
def relu(z):
return np.maximum(0, z)
def derivative(f, z, eps=0.000001):
return (f(z + eps) - f(z - eps)) / (2 * eps)
max_z = 2.5
z = np.linspace(-max_z, max_z, 200)
fig, axes = plt.subplots(nrows=2, ncols=4, figsize=(7, 3))
# Vẽ hàm Heaviside và đạo hàm
axes[0, 0].plot([-max_z, 0], [0, 0], "m-", linewidth=2)
axes[0, 0].plot(0, 0, "mx", markersize=7)
axes[0, 0].plot(0, 1, "mo", markersize=7)
axes[0, 0].plot([0, max_z], [1, 1], "m-", linewidth=2)
axes[0, 0].set_title("Heaviside", fontsize=12)
axes[1, 0].plot(z, derivative(np.sign, z), "m-", linewidth=2)
axes[1, 0].plot(0, 0, "mx", markersize=7)
axes[1, 0].set_ylabel("Đạo hàm", fontsize=12)
# Vẽ hàm ReLU và đạo hàm
axes[0, 1].plot(z, relu(z), "g-", linewidth=2)
axes[0, 1].set_title("ReLU", fontsize=12)
axes[1, 1].plot([-max_z, 0], [0, 0], "g-", linewidth=2)
axes[1, 1].plot([0, max_z], [1, 1], "g-", linewidth=2)
axes[1, 1].plot(0, 0, "gx", markersize=7)
axes[1, 1].plot(0, 1, "gx", markersize=7)
# Vẽ hàm Sigmoid và đạo hàm
axes[0, 2].plot(z, sigmoid(z), "r-", linewidth=2)
axes[0, 2].set_title("Sigmoid", fontsize=12)
axes[1, 2].plot(z, derivative(sigmoid, z), "r-", linewidth=2)
# Vẽ hàm Tanh và đạo hàm
axes[0, 3].plot(z, np.tanh(z), "b-", linewidth=1)
axes[0, 3].set_title("Tanh", fontsize=12)
axes[1, 3].plot(z, derivative(np.tanh, z), "b-", linewidth=1)
# Định dạng đồ thị
for row in range(2):
for col in range(4):
axes[row, col].grid(True)
if row == 0:
axes[row, col].set_xticklabels([])
if col == 2:
axes[row, col].set_xlim(-max_z, max_z)
axes[row, col].set_xticks([-2, -1, 0, 1, 2])
else:
axes[row, col].set_xlim(-1.3, 1.3)
axes[row, col].set_xticks([-1, 0, 1])
if col != 0 and ((row, col) != (0, 3)):
axes[row, col].set_yticklabels([])
if (row, col) == (0, 3):
axes[row, col].set_ylim(-1.3, 1.3)
axes[row, col].set_yticks([-1, 0, 1])
else:
axes[row, col].set_ylim(-0.5, 1.5)
axes[row, col].set_yticks([0, 1])
plt.show()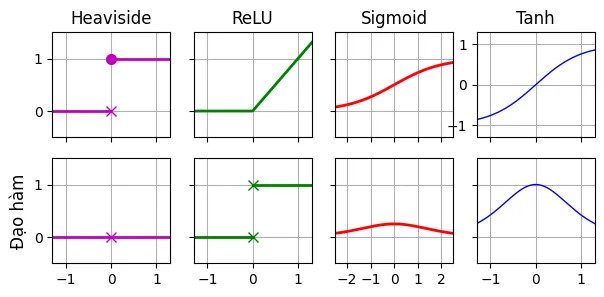
2. Xây dựng và Huấn luyện MLP với Scikit-Learn
Multi-Layer Perceptron (MLP) là mạng nơ-ron truyền thẳng (Feedforward Neural Network). Thuật toán cốt lõi để huấn luyện MLP là Lan truyền ngược (Backpropagation). Về mặt toán học, đây là việc áp dụng quy tắc chuỗi (Chain Rule) để tính gradient của hàm mất mát theo từng trọng số trong mạng: Sau đó, thuật toán Gradient Descent sẽ cập nhật trọng số để giảm thiểu hàm mất mát .
MLP cho bài toán Hồi quy (Regression MLPs)
Trong hồi quy, mục tiêu là tối ưu hóa hàm mất mát, thường là Sai số Trung bình Bình phương (MSE): (Trong đó là thành phần điều chuẩn L2 để tránh quá khớp).
Chúng ta sẽ sử dụng bộ dữ liệu California Housing để minh họa:
from sklearn.datasets import fetch_california_housing
from sklearn.metrics import root_mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPRegressor
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScalerDo một số thay đổi về nguồn dữ liệu gốc, chúng ta cần một hàm tùy chỉnh để tải dữ liệu một cách ổn định:
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
"""
# Chúng ta sẽ tải dữ liệu California Housing.
# Cách nhanh nhất là sử dụng fetch_california_housing() có sẵn của sklearn.datasets:
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
# Tuy nhiên, tính tại thời điểm viết bài viết này, link tải dữ liệu raw đã bị thay đổi và
# Sklearn chưa kịp cập nhật thay đổi này.
# Vì vậy, tạm thời, chúng ta sẽ dùng phương án "đi vòng" như dưới đây.
"""
import tarfile
import requests
from io import BytesIO
from sklearn.utils import Bunch
def fetch_california_housing_fixed():
"""
Tải dataset California Housing từ nguồn thay thế (Figshare) và trả về
đối tượng Bunch giống hệt sklearn.datasets.fetch_california_housing().
"""
# 1. Tải dữ liệu từ URL hoạt động
url = "https://figshare.com/ndownloader/files/5976036"
response = requests.get(url)
response.raise_for_status()
# 2. Giải nén và load dữ liệu thô
with tarfile.open(fileobj=BytesIO(response.content), mode="r:gz") as f:
file_content = f.extractfile("CaliforniaHousing/cal_housing.data")
cal_housing = np.loadtxt(file_content, delimiter=",")
# 3. Tiền xử lý (Theo đúng logic source code Sklearn)
# Sắp xếp lại cột theo thứ tự đúng
columns_index = [8, 7, 2, 3, 4, 5, 6, 1, 0]
cal_housing = cal_housing[:, columns_index]
# Tách Target và Features
target, data = cal_housing[:, 0], cal_housing[:, 1:]
# Feature Engineering (Chia cho số hộ gia đình để ra giá trị trung bình)
data[:, 2] /= data[:, 5] # AveRooms = TotalRooms / Households
data[:, 3] /= data[:, 5] # AveBedrms = TotalBedrms / Households
data[:, 5] = data[:, 4] / data[:, 5] # AveOccup = Population / Households
# Scale Target (đơn vị 100,000)
target = target / 100000.0
# 4. Định nghĩa thông tin mô tả (Metadata)
feature_names = [
"MedInc", "HouseAge", "AveRooms", "AveBedrms",
"Population", "AveOccup", "Latitude", "Longitude"
]
target_names = ["MedHouseVal"]
# Mô tả ngắn
descr = "California Housing dataset (Fixed download link). See sklearn documentation for details."
# 5. Trả về đối tượng Bunch chuẩn Sklearn
return Bunch(
data=data, # Numpy array (20640, 8)
target=target, # Numpy array (20640,)
feature_names=feature_names,
target_names=target_names,
DESCR=descr,
frame=None # Mặc định là None trừ khi as_frame=True
)
# Dòng này thay thế cho housing = fetch_california_housing()
housing = fetch_california_housing_fixed()
# Kiểm tra kết quả
print(f"Type: {type(housing)}")
print(f"Data shape: {housing.data.shape}")
print(f"Target shape: {housing.target.shape}")
print(f"Feature names: {housing.feature_names}")
output:
Type: <class 'sklearn.utils._bunch.Bunch'>
Data shape: (20640, 8)
Target shape: (20640,)
Feature names: ['MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'Population', 'AveOccup', 'Latitude', 'Longitude']Tiếp theo, Chia tập dữ liệu thành tập huấn luyện và tập kiểm tra:
# Chia tập dữ liệu thành tập huấn luyện và tập kiểm tra
X_train, X_test, y_train, y_test = train_test_split(
housing.data, housing.target, random_state=42)Tại sao phải chuẩn hóa dữ liệu (Scaling)?
Gradient Descent hội tụ nhanh hơn nhiều khi các đặc trưng có cùng tỷ lệ (scale). Nếu một đặc trưng có giá trị từ 0 đến 1, đặc trưng khác từ 0 đến 1000, các đường đồng mức (contours) của hàm mất mát sẽ bị kéo dãn thành hình elip rất dẹt, khiến Gradient Descent dao động mạnh và lâu hội tụ. StandardScaler thực hiện phép biến đổi để đưa dữ liệu về phân phối chuẩn tắc (mean=0, variance=1).
Dưới đây, chúng ta xây dựng MLPRegressor và sử dụng early_stopping.
Early Stopping là một kỹ thuật Regularization. Nó hoạt động bằng cách theo dõi lỗi trên tập kiểm định (validation set). Khi lỗi kiểm định bắt đầu tăng (dù lỗi huấn luyện vẫn giảm), điều đó có nghĩa là mô hình bắt đầu bị quá khớp (overfitting), và quá trình huấn luyện sẽ dừng lại.
# Cấu hình MLP Regressor
mlp_reg = MLPRegressor(hidden_layer_sizes=[50, 50, 50], early_stopping=True,
verbose=True, random_state=42)
# Tạo pipeline bao gồm bước chuẩn hóa dữ liệu và mô hình MLP
pipeline = make_pipeline(StandardScaler(), mlp_reg)
# Huấn luyện mô hình
pipeline.fit(X_train, y_train)output:
Iteration 1, loss = 0.85190332
Validation score: 0.534299
Iteration 2, loss = 0.28288639
Validation score: 0.651094
...
Iteration 45, loss = 0.12960481
Validation score: 0.788517
Validation score did not improve more than tol=0.000100 for 10 consecutive epochs. Stopping.Phân tích Output:
Quan sát output, ta thấy Validation score (hệ số trên tập validation) tăng dần và ổn định quanh mức 0.78-0.79. Quá trình dừng lại ở Iteration 45 vì điểm validation không cải thiện trong 10 vòng lặp liên tiếp (n_iter_no_change=10 mặc định), ngăn chặn việc học các nhiễu (noise) trong tập train.
# Điểm số tốt nhất trên tập kiểm định (validation score) trong quá trình huấn luyện
mlp_reg.best_validation_score_output:
0.791536125425778Sau khi huấn luyện, chúng ta đánh giá mô hình trên tập kiểm tra bằng chỉ số Căn bậc hai Sai số Trung bình Bình phương (RMSE - Root Mean Squared Error). RMSE cùng đơn vị với biến mục tiêu (ở đây là 100,000 USD), cho ta cảm nhận trực quan về sai số.
y_pred = pipeline.predict(X_test)
rmse = root_mean_squared_error(y_test, y_pred)rmseoutput:
0.5327699946812925Kết quả RMSE tương đương với sai số khoảng $53,300 (vì đơn vị target là $100k).
Biểu đồ phân tán dưới đây (Scatter Plot) so sánh giá trị thực tế () và giá trị dự đoán (). Nếu mô hình hoàn hảo, mọi điểm sẽ nằm trên đường chéo (đường màu đỏ).
plt.figure(figsize=(6, 6))
plt.scatter(y_test, y_pred, s=5, alpha=0.3)
plt.plot([0, 5.2], [0, 5.2], color='red', linestyle='--',
label="Dự đoán lý tưởng = Mục tiêu")
plt.axis("equal")
plt.xlabel("Giá trị thực tế")
plt.ylabel("Giá trị dự đoán")
plt.legend(fontsize=12)
plt.grid()
plt.show()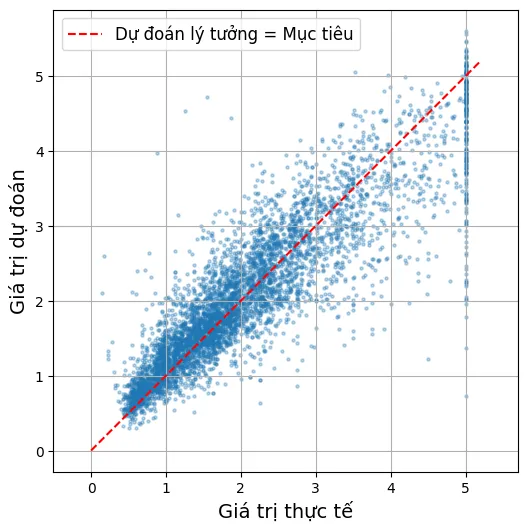
MLP cho bài toán Phân loại (Classification MLPs)
Đối với bài toán phân loại đa lớp (Multiclass Classification), lớp đầu ra của MLP sẽ sử dụng hàm kích hoạt Softmax. Cho vector đầu ra thô (logits) , xác suất của lớp được tính: Hàm này đảm bảo tổng xác suất của các lớp bằng 1: .
Hàm mất mát thường dùng là Cross-Entropy Loss (Log Loss): Hàm này phạt rất nặng nếu mô hình dự đoán xác suất thấp cho lớp đúng (khi thì ).
Chúng ta sẽ sử dụng bộ dữ liệu Fashion MNIST, bao gồm 70,000 ảnh thang độ xám kích thước . Đầu vào của MLP sẽ là vector phẳng hóa (flattened) có kích thước ().
from sklearn.datasets import fetch_openml
# Tải bộ dữ liệu Fashion-MNIST
fashion_mnist = fetch_openml(name="Fashion-MNIST", as_frame=False)
targets = fashion_mnist.target.astype(int)# Chia dữ liệu: 60,000 ảnh để huấn luyện, phần còn lại để kiểm tra
X_train, y_train = fashion_mnist.data[:60_000], targets[:60_000]
X_test, y_test = fashion_mnist.data[60_000:], targets[60_000:]X_sample = X_train[0].reshape(28, 28) # Chuyển đổi thành mảng 2 chiều để hiển thị
plt.figure(figsize=(1,1))
plt.imshow(X_sample, cmap="binary")
plt.axis('off')
plt.show()
Các nhãn tương ứng với các loại trang phục sau:
class_names = ["T-shirt/top", "Trouser", "Pullover", "Dress", "Coat",
"Sandal", "Shirt", "Sneaker", "Bag", "Ankle boot"]# Kiểm tra nhãn của ảnh đầu tiên
class_names[y_train[0]]output:
'Ankle boot'Để có cái nhìn tổng quan, hãy hiển thị một vài mẫu từ mỗi lớp:
# Mã bổ sung - Tạo Hình 9–10: Hiển thị các mẫu từ Fashion MNIST
n_rows = 4
plt.figure(figsize=(12, n_rows * 1.2))
for row in range(n_rows):
for class_index in range(10):
X_img = X_train[y_train==class_index][row].reshape(28, 28)
y_img = y_train[y_train==class_index][row]
plt.subplot(n_rows, 10, 10 * row + class_index + 1)
plt.imshow(X_img, cmap="binary", interpolation="nearest")
plt.axis('off')
if row == 0:
plt.title(class_names[y_img])
plt.subplots_adjust(wspace=0.2, hspace=0.5)
plt.show()
Vì dữ liệu hình ảnh có giá trị pixel từ 0 đến 255, chúng ta sử dụng MinMaxScaler để đưa về đoạn . Việc này giúp trọng số không bị bùng nổ và hàm kích hoạt không bị bão hòa.
from sklearn.neural_network import MLPClassifier
from sklearn.preprocessing import MinMaxScaler
# Khởi tạo MLP Classifier với 2 lớp ẩn (200 và 100 nơ-ron)
mlp_clf = MLPClassifier(hidden_layer_sizes=[200, 100], verbose=True,
early_stopping=True, random_state=42)
# Tạo pipeline chuẩn hóa và huấn luyện
pipeline = make_pipeline(MinMaxScaler(), mlp_clf)
pipeline.fit(X_train, y_train)
# Đánh giá độ chính xác trên tập kiểm tra
accuracy = pipeline.score(X_test, y_test)output:
Iteration 1, loss = 0.57483807
Validation score: 0.849333
...
Iteration 53, loss = 0.06864580
Validation score: 0.891500
Validation score did not improve more than tol=0.000100 for 10 consecutive epochs. Stopping.Phân tích Output: Hàm mất mát (Log Loss) giảm từ ~0.57 xuống ~0.06, cho thấy mô hình đang học rất tốt. Độ chính xác (Validation Score) đạt đỉnh khoảng 89.65% (ở iteration 42) trước khi dừng lại. Điều này chứng tỏ MLP có khả năng phân loại hình ảnh khá tốt, dù không sử dụng kiến trúc tích chập (CNN).
accuracyoutput:
0.8907mlp_clf.best_validation_score_output:
0.8965Lưu ý quan trọng: Khi gọi mlp_clf.score trực tiếp mà không qua pipeline, dữ liệu chưa được chuẩn hóa (MinMaxScaler), dẫn đến độ chính xác có thể thấp hơn.
# Lưu ý: mlp_clf chưa được chuẩn hóa đầu vào khi gọi trực tiếp nếu không qua pipeline
# Nhưng ở đây chúng ta chỉ gọi score để xem thuộc tính, tốt nhất nên dùng pipeline.score
mlp_clf.score(X_test, y_test) # Kết quả này có thể thấp nếu không scale dữ liệu đầu vào cho đúngoutput:
0.8713Thử dự đoán lớp cho một số hình ảnh đầu tiên trong tập kiểm tra:
X_new = X_test[:15] # Giả sử đây là 15 hình ảnh mới
mlp_clf.predict(X_new)output:
array([9, 2, 1, 1, 6, 1, 4, 6, 5, 7, 4, 5, 8, 3, 4])y_test[:15] # Nhãn thực tếoutput:
array([9, 2, 1, 1, 6, 1, 4, 6, 5, 7, 4, 5, 7, 3, 4])Mô hình dự đoán sai ở vị trí thứ 12 (index 12): Thực tế là lớp 7 (Sneaker), dự đoán là lớp 8 (Bag). Đây là sự nhầm lẫn thú vị cần phân tích sâu hơn bằng ma trận nhầm lẫn (confusion matrix).
Chúng ta cũng có thể xem xác suất dự đoán cho từng lớp (đầu ra của hàm Softmax).
y_proba = mlp_clf.predict_proba(X_new)
y_proba[12].round(2) # Làm tròn để dễ đọcoutput:
array([0., 0., 0., 0., 0., 0., 0., 0., 1., 0.])Phân tích độ tự tin (Confidence) của mô hình: Ở đây, mô hình dự đoán lớp 8 với xác suất xấp xỉ 1.0 (100%), tức là nó rất tự tin nhưng lại sai. Đây là hiện tượng “overconfidence” thường gặp ở các mạng nơ-ron sử dụng Cross-Entropy loss.
Đoạn mã dưới đây thống kê số lượng mẫu mà mô hình “thiếu tự tin” (xác suất cao nhất < 99.9%).
y_proba = mlp_clf.predict_proba(X_test)
(y_proba.max(axis=1) < 0.999).sum()output:
np.int64(24)y_proba.max(axis=1)output:
array([1., 1., 1., ..., 1., 1., 1.])y_proba = mlp_clf.predict_proba(X_test)
sum(y_proba.max(axis=1) < 0.99)output:
np.int64(16)Ôn tập & Cơ sở lý thuyết nâng cao
1. TensorFlow Playground: Hãy truy cập TensorFlow Playground. Quan sát cách các lớp ẩn trích xuất đặc trưng. Các nơ-ron ở lớp đầu thường học các đường biên đơn giản, trong khi các lớp sâu hơn tổ hợp chúng thành các hình dạng phức tạp (đa giác, xoắn ốc).
2. Mạng nơ-ron cho phép toán XOR: Bài toán XOR chứng minh giới hạn của mô hình tuyến tính (như Perceptron đơn lớp). XOR có bảng chân trị: (0,0)->0, (0,1)->1, (1,0)->1, (1,1)->0. Không thể vẽ một đường thẳng nào phân tách 2 lớp này. Giải pháp MLP: Cần ít nhất 1 lớp ẩn để biến đổi không gian. Cấu trúc ví dụ: (Cổng OR) (Cổng NAND) (Cổng AND) Kết hợp lại: .
3. Mạng MLP vs Hồi quy Logistic: Hồi quy Logistic (Logistic Regression) tương đương với một MLP có 0 lớp ẩn (chỉ có Input và Output layer với Softmax/Sigmoid). Vì vậy, nó chỉ có khả năng tạo ra các ranh giới quyết định tuyến tính (linear decision boundaries).
4. Tại sao hàm kích hoạt Sigmoid quan trọng ban đầu? Hàm bước (Step function) có đạo hàm bằng 0 hầu như mọi nơi, khiến , Gradient Descent không hoạt động. Sigmoid trơn (smooth) và có đạo hàm khác 0 , cho phép gradient “chảy” qua mạng. Tuy nhiên, với mạng rất sâu, Sigmoid gây ra lỗi Vanishing Gradient (do đạo hàm tối đa chỉ là 0.25).
5. Các hàm kích hoạt phổ biến:
- ReLU: Tốt nhất cho lớp ẩn (Hidden Layers). Tính toán nhanh, hội tụ nhanh.
- Softmax: Bắt buộc cho lớp đầu ra trong phân loại đa lớp.
- Sigmoid/Tanh: Thường dùng trong RNN hoặc các kiến trúc đặc biệt (như cổng trong LSTM).
6. Tính toán kích thước ma trận trong MLP: Đây là phần quan trọng để hiểu cách cài đặt (vectorization). Xét batch size . Lớp trước có nơ-ron, lớp sau có nơ-ron.
- Input matrix : .
- Weight matrix : .
- Bias vector : .
- Output (cộng bias theo cơ chế broadcasting). Kết quả kích thước .
7. Backpropagation (Lan truyền ngược): Đây là việc áp dụng Quy tắc chuỗi (Chain Rule) của giải tích. Cho hàm hợp , đạo hàm là . Trong mạng nơ-ron, để tìm gradient của Loss theo (lớp đầu), ta phải nhân gradient từ Loss về Output, từ Output về Lớp ẩn, từ Lớp ẩn về . Scikit-Learn sử dụng kỹ thuật Reverse-mode Automatic Differentiation.
8. Các siêu tham số (Hyperparameters):
- Hidden Layers/Neurons: Quyết định “dung lượng” (capacity) của mô hình. Quá ít -> Underfitting. Quá nhiều -> Overfitting.
- Learning Rate: Quan trọng nhất. Quá lớn -> phân kỳ. Quá nhỏ -> chậm.
- Activation: ReLU là mặc định an toàn.
Thực hành: Huấn luyện MLP trên bộ dữ liệu CoverType
Yêu cầu: Huấn luyện một Deep MLP trên bộ dữ liệu CoverType (sklearn.datasets.fetch_covtype()). Đây là bài toán phân loại loại rừng dựa trên các đặc trưng địa lý (độ cao, độ dốc, loại đất…). Dữ liệu có hơn 500,000 mẫu, yêu cầu tối ưu hóa tốt.
from sklearn.datasets import fetch_covtype
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
try:
# Cố gắng tải bộ dữ liệu CoverType theo cách chuẩn
covtype = fetch_covtype()
except Exception as e:
print(f"Cảnh báo: Lỗi tải từ nguồn mặc định ({e}). Đang tải từ nguồn dự phòng UCI...")
print("Quá trình này có thể mất vài giây do kích thước dữ liệu (~75MB nén)...")
# URL gốc từ UCI Machine Learning Repository
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/covtype/covtype.data.gz"
# Đọc dữ liệu trực tiếp bằng Pandas (hỗ trợ tự động giải nén gzip)
# File gốc không có hàng tiêu đề (header)
df = pd.read_csv(url, header=None)
# --- Tiền xử lý để khớp định dạng với sklearn.datasets.fetch_covtype ---
# 1. Tách đặc trưng (X) và nhãn (y)
# Trong file gốc, 54 cột đầu là đặc trưng, cột cuối cùng là nhãn (Target)
X = df.iloc[:, :-1].values
y = df.iloc[:, -1].values
# 2. Tạo class giả lập đối tượng Bunch của sklearn
class CovTypeData:
def __init__(self, data, target):
self.data = data # Numpy array
self.target = target # Numpy array
covtype = CovTypeData(X, y)
print("Đã tải và xử lý thành công dữ liệu CoverType từ nguồn dự phòng.")
# Chia tập dữ liệu. Bộ dữ liệu này khá lớn (~581k mẫu)
X_train, X_test, y_train, y_test = train_test_split(
covtype.data, covtype.target, random_state=42)output:
/usr/local/lib/python3.12/dist-packages/sklearn/datasets/_base.py:1519: UserWarning: Retry downloading from url: https://ndownloader.figshare.com/files/5976039
warnings.warn(f"Retry downloading from url: {remote.url}")
Cảnh báo: Lỗi tải từ nguồn mặc định (HTTP Error 403: Forbidden). Đang tải từ nguồn dự phòng UCI...
Quá trình này có thể mất vài giây do kích thước dữ liệu (~75MB nén)...
Đã tải và xử lý thành công dữ liệu CoverType từ nguồn dự phòng.Đối với dữ liệu lớn như CoverType (581,012 mẫu), Gradient Descent tiêu chuẩn (Full Batch) sẽ rất chậm. Scikit-Learn sử dụng Adam (một biến thể của Stochastic Gradient Descent) mặc định. Việc sử dụng StandardScaler là bắt buộc để Adam hội tụ hiệu quả.
# Cấu hình MLP Classifier
# - 3 lớp ẩn giảm dần: 200, 100, 50 nơ-ron (kiến trúc hình phễu)
# - early_stopping=True: Rất quan trọng với dữ liệu lớn để tiết kiệm thời gian
mlp_clf = MLPClassifier(hidden_layer_sizes=[200, 100, 50], early_stopping=True,
verbose=True, random_state=42)
# Tạo pipeline và huấn luyện
pipeline = make_pipeline(StandardScaler(), mlp_clf)
pipeline.fit(X_train, y_train)output:
Iteration 1, loss = 0.54176112
Validation score: 0.806751
...
Iteration 58, loss = 0.14782816
Validation score: 0.931912
Validation score did not improve more than tol=0.000100 for 10 consecutive epochs. Stopping.# Kiểm tra độ chính xác trên tập test
pipeline.score(X_test, y_test)output:
0.9325521675972269Kết luận: Mô hình đạt độ chính xác trên 93%, một kết quả rất ấn tượng cho bài toán đa lớp phức tạp. Điều này khẳng định sức mạnh của Deep MLP khi được kết hợp với chuẩn hóa dữ liệu và chiến lược tối ưu hóa phù hợp (Adam, Early Stopping).