[ML101] Chương 1: Tổng quan về Machine Learning
Giới thiệu tổng quan về Machine Learning, các loại hình học máy và ứng dụng thực tế
Bài viết có tham khảo, sử dụng và sửa đổi tài nguyên từ kho lưu trữ handson-mlp, tuân thủ giấy phép Apache‑2.0. Chúng tôi chân thành cảm ơn tác giả Aurélien Géron (@aureliengeron) vì sự chia sẻ kiến thức tuyệt vời và những đóng góp quý giá cho cộng đồng.
Chào mừng bạn đến với chương đầu tiên của loạt bài về Machine Learning.
Trong chương này, chúng ta sẽ tập trung vào nền tảng của quy trình xử lý dữ liệu và xây dựng mô hình cơ bản. Phần lớn nội dung sẽ được dành cho việc tiền xử lý (pre-processing) để tạo ra tập dữ liệu lifesat.csv – một tập dữ liệu thực tế mô tả mối quan hệ giữa mức độ Hài lòng với cuộc sống (Life satisfaction) và GDP bình quân đầu người (GDP per capita). Đây là bước đệm quan trọng, bởi trong khoa học dữ liệu, việc hiểu và chuẩn bị dữ liệu chiếm phần lớn thời gian và quyết định sự thành bại của mô hình.
Chúng ta sẽ tiếp cận các khái niệm dưới góc độ toán học thống kê và thực hành chạy code trên môi trường Google Colab.
Bạn có thể chạy trực tiếp các đoạn mã code tại: Google Colab.
1. Thiết lập môi trường trên Google Colab
Để đảm bảo tính nhất quán và khả năng tái lập (reproducibility) của các thí nghiệm, việc kiểm soát phiên bản phần mềm là nên làm. Các thuật toán và API trong Machine Learning thay đổi thường xuyên; do đó, chúng ta cần xác nhận môi trường thực thi đáp ứng đúng yêu cầu.
Đoạn mã dưới đây kiểm tra phiên bản Python. Chúng ta yêu cầu Python 3.10+ để tận dụng các tính năng mới về type hinting và tối ưu hóa hiệu năng:
import sys
# Kiểm tra xem phiên bản Python có lớn hơn hoặc bằng 3.10 không
assert sys.version_info >= (3, 10)Tiếp theo, chúng ta kiểm tra thư viện Scikit-Learn (sklearn). Đây là thư viện thông dụng cho các thuật toán Machine Learning cổ điển. Phiên bản 1.6.1 được yêu cầu để đảm bảo các hàm như LinearRegression hay KNeighborsRegressor hoạt động chính xác như trong Chương này.
from packaging.version import Version
import sklearn
# Kiểm tra phiên bản của thư viện Scikit-Learn
assert Version(sklearn.__version__) >= Version("1.6.1")Chúng ta cũng thiết lập cấu hình cho Matplotlib để đảm bảo các biểu đồ hiển thị rõ ràng, hỗ trợ việc phân tích định lượng trên đồ thị.
import matplotlib.pyplot as plt
# Thiết lập kích thước phông chữ chung là 12
plt.rc('font', size=12)
# Thiết lập kích thước phông chữ cho nhãn trục (x, y) là 14
plt.rc('axes', labelsize=14, titlesize=14)
# Thiết lập kích thước phông chữ cho chú thích (legend) là 12
plt.rc('legend', fontsize=12)
# Thiết lập kích thước phông chữ cho các vạch chia trên trục x và y là 10
plt.rc('xtick', labelsize=10)
plt.rc('ytick', labelsize=10)2. Hồi quy tuyến tính đơn giản (Simple Linear Regression)
Chúng ta bắt đầu với bài toán Hồi quy (Regression). Trong thống kê học, hồi quy là phương pháp mô hình hóa mối quan hệ giữa một biến phụ thuộc (biến mục tiêu - Life satisfaction) và một hoặc nhiều biến độc lập (biến giải thích - GDP per capita).
Mô hình Hồi quy tuyến tính (Linear Regression) giả định mối quan hệ này là tuyến tính, được biểu diễn bằng phương trình:
Trong đó:
- là giá trị dự đoán.
- là giá trị đầu vào (GDP).
- (bias/intercept) và (weight/slope) là các tham số mô hình cần tìm.
Quy trình thực nghiệm bao gồm:
- Data Loading: Tải dữ liệu vào bộ nhớ.
- Exploratory Data Analysis (EDA): Trực quan hóa để cảm nhận phân phối dữ liệu.
- Model Selection: Chọn giả thuyết (hypothesis space) phù hợp.
- Training: Tìm tham số tối ưu .
- Inference: Dự đoán trên mẫu mới.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
# Tải và chuẩn bị dữ liệu
data_root = "https://github.com/ageron/data/raw/main/"
# Đọc file CSV chứa dữ liệu về sự hài lòng cuộc sống và GDP
lifesat = pd.read_csv(data_root + "lifesat/lifesat.csv")
# Tách biệt biến đầu vào (X) và biến mục tiêu (y)
# X là GDP bình quân đầu người
X = lifesat[["GDP per capita (USD)"]].values
# y là Chỉ số hài lòng cuộc sống
y = lifesat[["Life satisfaction"]].values
# Trực quan hóa dữ liệu
# Vẽ biểu đồ phân tán (scatter plot) để xem sự phân bố của dữ liệu
lifesat.plot(kind='scatter', grid=True,
x="GDP per capita (USD)", y="Life satisfaction")
# Thiết lập giới hạn cho các trục để tập trung vào vùng dữ liệu quan trọng
plt.axis([23_500, 62_500, 4, 9])
plt.show()
# Lựa chọn mô hình tuyến tính
model = LinearRegression()
# Huấn luyện mô hình
# Hàm fit() sẽ tìm ra các tham số tối ưu cho mô hình dựa trên dữ liệu X và y
model.fit(X, y)
# Thực hiện dự đoán cho Puerto Rico
# Puerto Rico có GDP bình quân đầu người năm 2020 là khoảng 33,442.8 USD
X_new = [[33_442.8]]
print(model.predict(X_new)) # Kết quả dự đoán: [[6.01610329]]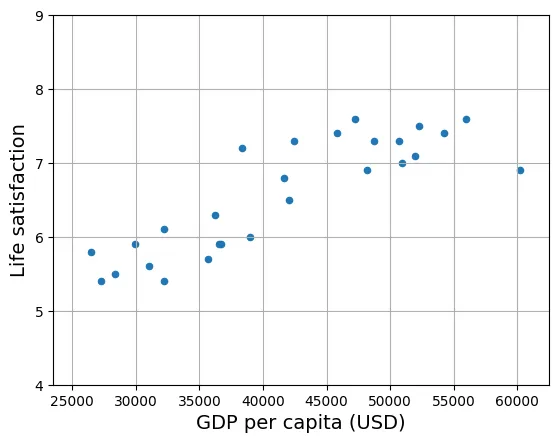
output:
[[6.01610329]]Phân tích Code và Kết quả:
Xđược định dạng là mảng 2 chiều (matrix)[[value1], [value2], ...]vì Scikit-Learn yêu cầu đầu vào là ma trận đặc trưng (feature matrix) kích thước .model.fit(X, y): Bản chất toán học ở đây là giải bài toán tối ưu hóa. Cụ thể, thuật toán tìm để tối thiểu hóa hàm mất mát (Cost Function), thường là Sai số bình phương trung bình (MSE):- Kết quả dự đoán
6.016cho thấy với mức GDP ~33k USD, mô hình kỳ vọng mức độ hài lòng cuộc sống là khoảng 6/10.
Thay thế bằng mô hình k-Láng giềng gần nhất (k-Nearest Neighbors)
Hồi quy tuyến tính thuộc nhóm Học dựa trên mô hình (Model-based learning) (học tham số). Một cách tiếp cận khác là Học dựa trên trường hợp (Instance-based learning), điển hình là k-NN.
Thay vì cố gắng tìm một hàm toán học tổng quát, k-NN ghi nhớ dữ liệu huấn luyện. Khi cần dự đoán cho điểm mới , nó tìm điểm dữ liệu gần nhất trong không gian đặc trưng và tính trung bình giá trị mục tiêu của chúng:
Trong đó là tập hợp láng giềng gần nhất.
# Chọn mô hình Hồi quy 3-Láng giềng gần nhất (3-Nearest Neighbors regression)
from sklearn.neighbors import KNeighborsRegressor
# Khởi tạo mô hình với tham số n_neighbors = 3
model = KNeighborsRegressor(n_neighbors=3)
# Huấn luyện mô hình
# Tương tự như trên, hàm fit() sẽ lưu trữ dữ liệu để dùng cho việc tra cứu sau này
model.fit(X, y)
# Thực hiện dự đoán cho Puerto Rico
print(model.predict(X_new)) # Kết quả dự đoán: [[5.73333333]]output:
[[5.73333333]]Phân tích:
n_neighbors=3: Đây là một siêu tham số (hyperparameter). Nếu , mô hình rất nhạy với nhiễu (overfitting). Nếu quá lớn, mô hình trở nên quá mượt và mất đi các chi tiết cục bộ (underfitting).- Kết quả dự đoán là
5.733, thấp hơn một chút so với hồi quy tuyến tính, phản ánh sự khác biệt trong cách tiếp cận của hai thuật toán đối với cấu trúc dữ liệu cục bộ.
3. Quy trình xử lý và tạo dữ liệu (Data Engineering Pipeline)
Phần này minh họa quy trình ETL (Extract, Transform, Load) để tạo ra tập dữ liệu lifesat.csv. Đây là kỹ năng cốt lõi của Data Scientist.
Dữ liệu thực tế thường phân tán, nhiễu và không đồng nhất. Để xây dựng tập dữ liệu sạch, chúng ta cần kết hợp dữ liệu từ OECD (Chỉ số cuộc sống) và World Bank (GDP).
Tải và chuẩn bị dữ liệu
Sử dụng thư viện chuẩn urllib để tải dữ liệu thô từ repository.
from pathlib import Path
import urllib.request
# Tạo đường dẫn thư mục để lưu dữ liệu
datapath = Path() / "datasets" / "lifesat"
datapath.mkdir(parents=True, exist_ok=True)
data_root = "https://github.com/ageron/data/raw/main/"
# Vòng lặp tải các file csv cần thiết nếu chưa tồn tại
for filename in ("oecd_bli.csv", "gdp_per_capita.csv"):
if not (datapath / filename).is_file():
print("Downloading", filename)
url = data_root + "lifesat/" + filename
urllib.request.urlretrieve(url, datapath / filename)
# Đọc dữ liệu vào DataFrame của pandas
oecd_bli = pd.read_csv(datapath / "oecd_bli.csv")
gdp_per_capita = pd.read_csv(datapath / "gdp_per_capita.csv")output:
Downloading oecd_bli.csv
Downloading gdp_per_capita.csvTiền xử lý dữ liệu GDP
Dữ liệu chuỗi thời gian (time-series) của GDP cần được cắt lát (slicing) để lấy một thời điểm cụ thể (snapshot) nhằm phù hợp với bài toán hồi quy tĩnh.
# Chỉ lấy dữ liệu năm 2020
gdp_year = 2020
gdppc_col = "GDP per capita (USD)"
lifesat_col = "Life satisfaction"
# Lọc dữ liệu theo năm
gdp_per_capita = gdp_per_capita[gdp_per_capita["Year"] == gdp_year]
# Bỏ các cột không cần thiết
gdp_per_capita = gdp_per_capita.drop(["Code", "Year"], axis=1)
# Đổi tên cột
gdp_per_capita.columns = ["Country", gdppc_col]
# Đặt tên quốc gia làm chỉ mục (index)
gdp_per_capita.set_index("Country", inplace=True)
# Hiển thị 5 dòng đầu tiên
gdp_per_capita.head()output:
GDP per capita (USD)
Country
Afghanistan 1978.961579
Africa Eastern and Southern 3387.594670
Africa Western and Central 4003.158913
Albania 13295.410885
Algeria 10681.679297Tiền xử lý dữ liệu OECD BLI
Bảng dữ liệu OECD BLI đang ở dạng “dài” (long format), trong đó các chỉ số nằm trong cùng một cột Indicator. Chúng ta cần xoay (pivot) bảng này sang dạng “rộng” (wide format) để mỗi chỉ số (như Life Satisfaction) trở thành một đặc trưng (feature) riêng biệt.
# Lọc dữ liệu tổng thể (TOT)
oecd_bli = oecd_bli[oecd_bli["INEQUALITY"]=="TOT"]
# Xoay bảng dữ liệu để mỗi chỉ báo (Indicator) thành một cột
oecd_bli = oecd_bli.pivot(index="Country", columns="Indicator", values="Value")
# Hiển thị 5 dòng đầu tiên
oecd_bli.head()output:
Indicator Air pollution Dwellings without basic facilities \
Country
Australia 5.0 NaN
Austria 16.0 0.9
Belgium 15.0 1.9
Brazil 10.0 6.7
Canada 7.0 0.2
Indicator Educational attainment Employees working very long hours \
Country
Australia 81.0 13.04
Austria 85.0 6.66
Belgium 77.0 4.75
Brazil 49.0 7.13
Canada 91.0 3.69
Indicator Employment rate Feeling safe walking alone at night \
Country
Australia 73.0 63.5
Austria 72.0 80.6
Belgium 63.0 70.1
Brazil 61.0 35.6
Canada 73.0 82.2
Indicator Homicide rate Household net adjusted disposable income \
Country
Australia 1.1 32759.0
Austria 0.5 33541.0
Belgium 1.0 30364.0
Brazil 26.7 NaN
Canada 1.3 30854.0
Indicator Household net wealth Housing expenditure ... Personal earnings \
Country ...
Australia 427064.0 20.0 ... 49126.0
Austria 308325.0 21.0 ... 50349.0
Belgium 386006.0 21.0 ... 49675.0
Brazil NaN NaN ... NaN
Canada 423849.0 22.0 ... 47622.0
Indicator Quality of support network Rooms per person Self-reported health \
Country
Australia 95.0 NaN 85.0
Austria 92.0 1.6 70.0
Belgium 91.0 2.2 74.0
Brazil 90.0 NaN NaN
Canada 93.0 2.6 88.0
Indicator Stakeholder engagement for developing regulations Student skills \
Country
Australia 2.7 502.0
Austria 1.3 492.0
Belgium 2.0 503.0
Brazil 2.2 395.0
Canada 2.9 523.0
Indicator Time devoted to leisure and personal care Voter turnout \
Country
Australia 14.35 91.0
Austria 14.55 80.0
Belgium 15.70 89.0
Brazil NaN 79.0
Canada 14.56 68.0
Indicator Water quality Years in education
Country
Australia 93.0 21.0
Austria 92.0 17.0
Belgium 84.0 19.3
Brazil 73.0 16.2
Canada 91.0 17.3
[5 rows x 24 columns]Gộp dữ liệu (Merging)
Bước này thực hiện phép giao (intersection) giữa hai tập dữ liệu dựa trên khóa chính là Country.
# Gộp hai bảng dữ liệu dựa trên index (tên quốc gia)
full_country_stats = pd.merge(left=oecd_bli, right=gdp_per_capita,
left_index=True, right_index=True)
# Sắp xếp theo GDP tăng dần
full_country_stats.sort_values(by=gdppc_col, inplace=True)
# Chỉ giữ lại hai cột quan trọng
full_country_stats = full_country_stats[[gdppc_col, lifesat_col]]
# Hiển thị 5 dòng đầu tiên
full_country_stats.head()output:
GDP per capita (USD) Life satisfaction
Country
South Africa 11466.189672 4.7
Colombia 13441.492952 6.3
Brazil 14063.982505 6.4
Mexico 17887.750736 6.5
Chile 23324.524751 6.5Lọc dữ liệu để minh họa vấn đề Quá khớp (Overfitting)
Chúng ta chủ đích loại bỏ các giá trị ngoại lai (outliers) hoặc các điểm dữ liệu cực đoan (quá giàu hoặc quá nghèo) trong bước này. Mục đích sư phạm là để tạo ra một tập dữ liệu có xu hướng tuyến tính rõ ràng, từ đó dễ dàng minh họa mô hình Linear Regression. Nếu giữ lại toàn bộ, mối quan hệ sẽ phi tuyến tính phức tạp hơn nhiều.
min_gdp = 23_500
max_gdp = 62_500
# Lọc các quốc gia có GDP nằm trong khoảng xác định
country_stats = full_country_stats[(full_country_stats[gdppc_col] >= min_gdp) &
(full_country_stats[gdppc_col] <= max_gdp)]
country_stats.head()output:
GDP per capita (USD) Life satisfaction
Country
Russia 26456.387938 5.8
Greece 27287.083401 5.4
Turkey 28384.987785 5.5
Latvia 29932.493910 5.9
Hungary 31007.768407 5.6Lưu trữ dữ liệu đã xử lý để đảm bảo tính tái lập cho các thí nghiệm sau:
country_stats.to_csv(datapath / "lifesat.csv")
full_country_stats.to_csv(datapath / "lifesat_full.csv")Trực quan hóa dữ liệu đã lọc
Biểu đồ này đánh dấu vị trí của một số quốc gia đại diện. Việc này giúp chúng ta có cái nhìn trực quan về mối tương quan dương (positive correlation) giữa GDP và độ hài lòng cuộc sống trong khoảng thu nhập trung bình-cao này.
# Vẽ biểu đồ phân tán cơ bản
country_stats.plot(kind='scatter', figsize=(5, 3), grid=True,
x=gdppc_col, y=lifesat_col)
min_life_sat = 4
max_life_sat = 9
# Danh sách vị trí text chú thích cho các quốc gia
position_text = {
"Turkey": (29_500, 4.2),
"Hungary": (28_000, 6.9),
"France": (40_000, 5),
"New Zealand": (28_000, 8.2),
"Australia": (50_000, 5.5),
"United States": (59_000, 5.3),
"Denmark": (46_000, 8.5)}
# Vòng lặp để vẽ mũi tên và tên quốc gia
for country, pos_text in position_text.items():
pos_data_x = country_stats[gdppc_col].loc[country]
pos_data_y = country_stats[lifesat_col].loc[country]
country = "US" if country == "United States" else country
plt.annotate(country, xy=(pos_data_x, pos_data_y),
xytext=pos_text, fontsize=12,
arrowprops=dict(facecolor='black', width=0.5,
shrink=0.08, headwidth=5))
plt.plot(pos_data_x, pos_data_y, "ro") # Đánh dấu điểm màu đỏ
plt.axis([min_gdp, max_gdp, min_life_sat, max_life_sat])
plt.show()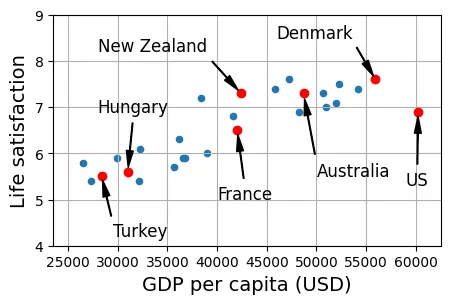
Dưới đây là bảng dữ liệu chi tiết cho các điểm được đánh dấu trên biểu đồ:
highlighted_countries = country_stats.loc[list(position_text.keys())]
highlighted_countries[[gdppc_col, lifesat_col]].sort_values(by=gdppc_col)output:
GDP per capita (USD) Life satisfaction
Country
Turkey 28384.987785 5.5
Hungary 31007.768407 5.6
France 42025.617373 6.5
New Zealand 42404.393738 7.3
Australia 48697.837028 7.3
Denmark 55938.212809 7.6
United States 60235.728492 6.94. Tham số mô hình (Model Parameters)
Một mô hình tuyến tính được định nghĩa hoàn toàn bởi các tham số của nó. Với một biến đầu vào, chúng ta có phương trình đường thẳng:
- (Intercept): Điểm cắt trục tung. Giá trị dự đoán khi GDP = 0.
- (Slope): Độ dốc. Mức tăng kỳ vọng của độ hài lòng khi GDP tăng thêm 1 đơn vị.
Mục tiêu của thuật toán học là tìm bộ tham số tối ưu. Hình dưới đây minh họa ba giả thuyết (hypothesis) khác nhau. Đường màu xanh dương có vẻ khớp dữ liệu nhất, trong khi đường đỏ và xanh lá cây có sai số rất lớn.
country_stats.plot(kind='scatter', figsize=(5, 3), grid=True,
x=gdppc_col, y=lifesat_col)
X = np.linspace(min_gdp, max_gdp, 1000)
# Đường màu đỏ: tham số ngẫu nhiên
w1, w2 = 4.2, 0
plt.plot(X, w1 + w2 * 1e-5 * X, "r")
plt.text(40_000, 4.9, fr"$\theta_0 = {w1}$", color="r")
plt.text(40_000, 4.4, fr"$\theta_1 = {w2}$", color="r")
# Đường màu xanh lá: tham số ngẫu nhiên khác
w1, w2 = 10, -9
plt.plot(X, w1 + w2 * 1e-5 * X, "g")
plt.text(26_000, 8.5, fr"$\theta_0 = {w1}$", color="g")
plt.text(26_000, 8.0, fr"$\theta_1 = {w2} \times 10^{{-5}}$", color="g")
# Đường màu xanh dương: tham số có vẻ hợp lý hơn
w1, w2 = 3, 8
plt.plot(X, w1 + w2 * 1e-5 * X, "b")
plt.text(48_000, 8.5, fr"$\theta_0 = {w1}$", color="b")
plt.text(48_000, 8.0, fr"$\theta_1 = {w2} \times 10^{{-5}}$", color="b")
plt.axis([min_gdp, max_gdp, min_life_sat, max_life_sat])
plt.show()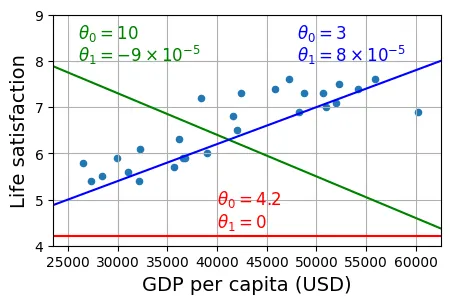
Tìm tham số tối ưu (Optimization)
Trong Scikit-Learn, hàm fit() sử dụng phương pháp Bình phương Tối thiểu thường (Ordinary Least Squares - OLS). Về mặt toán học, nó giải hệ phương trình để tìm nghiệm chính xác giúp giảm thiểu tổng bình phương sai số dư (Residual Sum of Squares - RSS).
from sklearn import linear_model
X_sample = country_stats[[gdppc_col]].values
y_sample = country_stats[[lifesat_col]].values
# Khởi tạo và huấn luyện mô hình
lin1 = linear_model.LinearRegression()
lin1.fit(X_sample, y_sample)
# Lấy ra tham số đã học được
t0, t1 = lin1.intercept_[0], lin1.coef_[0][0]
print(f"θ0={t0:.2f}, θ1={t1:.2e}")output:
θ0=3.75, θ1=6.78e-05Kết quả cho thấy một mối tương quan dương nhỏ: khi GDP tăng, sự hài lòng có xu hướng tăng, nhưng độ dốc không quá lớn do đơn vị của GDP là USD (giá trị lớn).
Dưới đây là trực quan hóa đường hồi quy tối ưu chồng lên dữ liệu thực tế:
country_stats.plot(kind='scatter', figsize=(5, 3), grid=True,
x=gdppc_col, y=lifesat_col)
X = np.linspace(min_gdp, max_gdp, 1000)
# Vẽ đường hồi quy tuyến tính với tham số t0, t1 vừa tìm được
plt.plot(X, t0 + t1 * X, "b")
plt.text(max_gdp - 20_000, min_life_sat + 1.9,
fr"$\theta_0 = {t0:.2f}$", color="b")
plt.text(max_gdp - 20_000, min_life_sat + 1.3,
fr"$\theta_1 = {t1 * 1e5:.2f} \times 10^{{-5}}$", color="b")
plt.axis([min_gdp, max_gdp, min_life_sat, max_life_sat])
plt.show()
Dự đoán (Inference)
Khi mô hình đã học được , việc dự đoán chỉ đơn giản là phép nhân ma trận (hoặc thay số vào công thức).
Lấy dữ liệu GDP của Puerto Rico:
puerto_rico_gdp_per_capita = gdp_per_capita[gdppc_col].loc["Puerto Rico"]
puerto_rico_gdp_per_capitaoutput:
np.float64(33442.8315702748)Áp dụng mô hình:
puerto_rico_predicted_life_satisfaction = lin1.predict(
[[puerto_rico_gdp_per_capita]])[0, 0]
puerto_rico_predicted_life_satisfactionoutput:
np.float64(6.016105434473317)Hình dưới đây minh họa quá trình suy diễn: tìm giá trị của Puerto Rico trên trục hoành, gióng lên đường hồi quy (đường xanh), và tìm giá trị tương ứng trên trục tung.
country_stats.plot(kind='scatter', figsize=(5, 3), grid=True,
x=gdppc_col, y=lifesat_col)
X = np.linspace(min_gdp, max_gdp, 1000)
plt.plot(X, t0 + t1 * X, "b")
plt.text(min_gdp + 22_000, max_life_sat - 1.1,
fr"$\theta_0 = {t0:.2f}$", color="b")
plt.text(min_gdp + 22_000, max_life_sat - 0.6,
fr"$\theta_1 = {t1 * 1e5:.2f} \times 10^{{-5}}$", color="b")
# Vẽ đường gióng thể hiện dự đoán cho Puerto Rico
plt.plot([puerto_rico_gdp_per_capita, puerto_rico_gdp_per_capita],
[min_life_sat, puerto_rico_predicted_life_satisfaction], "r--")
plt.text(puerto_rico_gdp_per_capita + 1000, 5.0,
fr"Prediction = {puerto_rico_predicted_life_satisfaction:.2f}",
color="r")
plt.plot(puerto_rico_gdp_per_capita, puerto_rico_predicted_life_satisfaction,
"ro")
plt.axis([min_gdp, max_gdp, min_life_sat, max_life_sat])
plt.show()
5. Sự đại diện của dữ liệu (Data Representativeness)
Một vấn đề cốt yếu trong thống kê là Bias mẫu (Sampling Bias). Mô hình của chúng ta hoạt động tốt trên các quốc gia trung bình-khá, nhưng liệu nó có tổng quát hóa được cho toàn thế giới?
Hãy xem xét các quốc gia “ngoại lai” mà chúng ta đã lọc bỏ trước đó (các nước rất nghèo hoặc rất giàu).
# Lấy các quốc gia nằm ngoài khoảng min_gdp và max_gdp
missing_data = full_country_stats[(full_country_stats[gdppc_col] < min_gdp) |
(full_country_stats[gdppc_col] > max_gdp)]
missing_dataoutput:
GDP per capita (USD) Life satisfaction
Country
South Africa 11466.189672 4.7
Colombia 13441.492952 6.3
Brazil 14063.982505 6.4
Mexico 17887.750736 6.5
Chile 23324.524751 6.5
Norway 63585.903514 7.6
Switzerland 68393.306004 7.5
Ireland 89688.956958 7.0
Luxembourg 110261.157353 6.9Khi đưa các dữ liệu này vào biểu đồ, chúng ta thấy rõ tính phi tuyến tính.
- Ở các nước nghèo, GDP tăng nhẹ cũng làm tăng đáng kể sự hài lòng.
- Ở các nước rất giàu, quy luật “thu hoạch giảm dần” (diminishing returns) xuất hiện: GDP tăng thêm không làm tăng nhiều sự hài lòng, thậm chí có thể giảm.
Biểu đồ dưới so sánh hai mô hình:
- Đường chấm xanh (Partial Data): Mô hình cũ, bị bias do thiếu dữ liệu.
- Đường đen (Full Data): Mô hình mới huấn luyện trên toàn bộ dữ liệu.
Đường đen có độ dốc thấp hơn và chặn trên cao hơn, cố gắng trung hòa giữa các nhóm dữ liệu nhưng vẫn không thể khớp tốt hoàn toàn do bản chất dữ liệu là phi tuyến tính (cong), trong khi mô hình là tuyến tính (thẳng). Đây là ví dụ về Underfitting (Mô hình quá đơn giản so với dữ liệu).
position_text_missing_countries = {
"South Africa": (20_000, 4.2),
"Colombia": (6_000, 8.2),
"Brazil": (18_000, 7.8),
"Mexico": (24_000, 7.4),
"Chile": (30_000, 7.0),
"Norway": (51_000, 6.2),
"Switzerland": (62_000, 5.7),
"Ireland": (81_000, 5.2),
"Luxembourg": (92_000, 4.7),}
full_country_stats.plot(kind='scatter', figsize=(8, 3),
x=gdppc_col, y=lifesat_col, grid=True)
# Đánh dấu các quốc gia bị thiếu
for country, pos_text in position_text_missing_countries.items():
pos_data_x, pos_data_y = missing_data.loc[country]
plt.annotate(country, xy=(pos_data_x, pos_data_y),
xytext=pos_text, fontsize=12,
arrowprops=dict(facecolor='black', width=0.5,
shrink=0.08, headwidth=5))
plt.plot(pos_data_x, pos_data_y, "rs")
# Đường hồi quy trên tập dữ liệu một phần (cũ)
X = np.linspace(0, 115_000, 1000)
plt.plot(X, t0 + t1 * X, "b:")
# Huấn luyện mô hình mới trên toàn bộ dữ liệu
lin_reg_full = linear_model.LinearRegression()
Xfull = np.c_[full_country_stats[gdppc_col]]
yfull = np.c_[full_country_stats[lifesat_col]]
lin_reg_full.fit(Xfull, yfull)
t0full, t1full = lin_reg_full.intercept_[0], lin_reg_full.coef_[0][0]
# Đường hồi quy trên toàn bộ dữ liệu (mới)
X = np.linspace(0, 115_000, 1000)
plt.plot(X, t0full + t1full * X, "k")
plt.axis([0, 115_000, min_life_sat, max_life_sat])
plt.show()
6. Vấn đề Quá khớp (Overfitting)
Ngược lại với Underfitting là Overfitting. Điều này xảy ra khi mô hình quá phức tạp, có quá nhiều bậc tự do (degrees of freedom), dẫn đến việc nó “học thuộc lòng” cả những nhiễu (noise) trong dữ liệu huấn luyện thay vì học quy luật tổng quát.
Ví dụ dưới đây sử dụng Hồi quy đa thức (Polynomial Regression) bậc 10:
Với bậc cao như vậy, đường cong có thể uốn lượn dữ dội để đi qua hầu hết các điểm dữ liệu. Mặc dù sai số trên tập huấn luyện rất thấp, nhưng khả năng dự đoán trên dữ liệu mới (ví dụ: các khoảng trống giữa các điểm) sẽ cực kỳ tệ.
Code sử dụng Pipeline để kết hợp các bước:
PolynomialFeatures: Tạo ra các biến mũ .StandardScaler: Chuẩn hóa dữ liệu (quan trọng với hồi quy đa thức để tránh bùng nổ giá trị số).LinearRegression: Hồi quy tuyến tính trên không gian đặc trưng mới.
from sklearn import preprocessing
from sklearn import pipeline
full_country_stats.plot(kind='scatter', figsize=(8, 3),
x=gdppc_col, y=lifesat_col, grid=True)
# Tạo đặc trưng đa thức bậc 10
poly = preprocessing.PolynomialFeatures(degree=10, include_bias=False)
scaler = preprocessing.StandardScaler()
lin_reg2 = linear_model.LinearRegression()
# Tạo một pipeline xử lý: Tạo đa thức -> Chuẩn hóa dữ liệu -> Hồi quy tuyến tính
pipeline_reg = pipeline.Pipeline([
('poly', poly),
('scal', scaler),
('lin', lin_reg2)])
# Huấn luyện
pipeline_reg.fit(Xfull, yfull)
curve = pipeline_reg.predict(X[:, np.newaxis])
# Vẽ đường cong dự đoán
plt.plot(X, curve)
plt.axis([0, 115_000, min_life_sat, max_life_sat])
plt.show()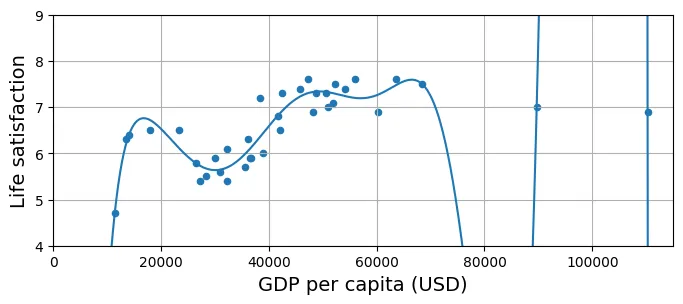
Overfitting cũng có thể xảy ra khi chúng ta cố tìm các quy luật ngẫu nhiên không có ý nghĩa thống kê. Ví dụ: “Các quốc gia có chữ W trong tên thì có mức độ hài lòng cao”. Đây là sự trùng hợp ngẫu nhiên (spurious correlation).
w_countries = [c for c in full_country_stats.index if "W" in c.upper()]
full_country_stats.loc[w_countries][lifesat_col]output:
Life satisfaction
Country
New Zealand 7.3
Sweden 7.3
Norway 7.6
Switzerland 7.5
dtype: float64Nhưng khi nhìn vào dữ liệu toàn cầu, quy luật này vỡ vụn (các nước nghèo như Rwanda, Zimbabwe cũng có chữ W). Nếu mô hình học quy luật này, nó sẽ dự đoán sai hoàn toàn cho Rwanda.
all_w_countries = [c for c in gdp_per_capita.index if "W" in c.upper()]
gdp_per_capita.loc[all_w_countries].sort_values(by=gdppc_col)output:
GDP per capita (USD)
Country
Malawi 1486.778248
Rwanda 2098.710362
Zimbabwe 2744.690758
Africa Western and Central 4003.158913
Papua New Guinea 4101.218882
Lower middle income 6722.809932
Eswatini 8392.717564
Low & middle income 10293.855325
Arab World 13753.707307
Botswana 16040.008473
World 16194.040310
New Zealand 42404.393738
Sweden 50683.323510
Norway 63585.903514
Switzerland 68393.3060047. Chính quy hóa (Regularization)
Để chống lại Overfitting mà không cần giảm bậc của mô hình một cách thủ công, chúng ta sử dụng Chính quy hóa (Regularization). Kỹ thuật này thêm một thành phần phạt (penalty term) vào hàm mất mát để hạn chế độ lớn của các tham số .
Ridge Regression (Hồi quy Ridge) tối thiểu hóa hàm chi phí sau:
Trong đó:
- Thành phần đầu là sai số dự đoán.
- Thành phần sau là hình phạt L2 (bình phương trọng số).
- (alpha) là siêu tham số kiểm soát mức độ phạt.
Nếu rất lớn, thuật toán buộc các phải rất nhỏ (gần bằng 0), làm cho đường hồi quy trở nên phẳng hơn, ít nhạy cảm với dữ liệu huấn luyện, từ đó giảm phương sai (variance) nhưng tăng độ lệch (bias).
Trong biểu đồ dưới:
blue dotted: Mô hình tuyến tính thường trên dữ liệu cục bộ (Rất dốc, biased).blue dashed: Mô hình Ridge () trên dữ liệu cục bộ. Đường này phẳng hơn và gần với đường đen (mô hình toàn cục) hơn. Điều này chứng minh Regularization giúp mô hình tổng quát hóa tốt hơn ngay cả khi học trên dữ liệu không đầy đủ.
country_stats.plot(kind='scatter', x=gdppc_col, y=lifesat_col, figsize=(8, 3))
missing_data.plot(kind='scatter', x=gdppc_col, y=lifesat_col,
marker="s", color="r", grid=True, ax=plt.gca())
X = np.linspace(0, 115_000, 1000)
# Vẽ mô hình tuyến tính thường (trên dữ liệu một phần)
plt.plot(X, t0 + t1*X, "b:", label="Linear model on partial data")
# Vẽ mô hình tuyến tính trên toàn bộ dữ liệu
plt.plot(X, t0full + t1full * X, "k-", label="Linear model on all data")
# Huấn luyện mô hình Ridge với alpha lớn (chính quy hóa mạnh)
ridge = linear_model.Ridge(alpha=10**9.5)
X_sample = country_stats[[gdppc_col]]
y_sample = country_stats[[lifesat_col]]
ridge.fit(X_sample, y_sample)
# Lấy tham số và vẽ
t0ridge, t1ridge = ridge.intercept_[0], ridge.coef_[0]
plt.plot(X, t0ridge + t1ridge * X, "b--",
label="Regularized linear model on partial data")
plt.legend(loc="lower right")
plt.axis([0, 115_000, min_life_sat, max_life_sat])
plt.show()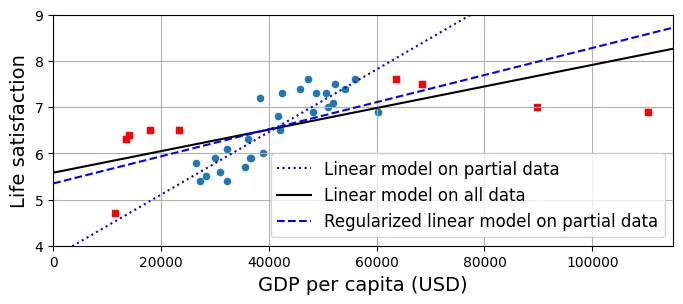
8. Ôn tập kiến thức cốt lõi
1. Định nghĩa Machine Learning (ML)? ML là lĩnh vực nghiên cứu giúp máy tính có khả năng học từ dữ liệu mà không cần được lập trình rõ ràng cho từng quy tắc cụ thể. Theo Tom Mitchell: Một chương trình được coi là học từ kinh nghiệm E đối với tác vụ T và đo lường hiệu suất P, nếu hiệu suất P của nó ở tác vụ T được cải thiện theo kinh nghiệm E.
2. Ứng dụng chính của ML? Giải quyết các bài toán phức tạp không có thuật toán cố định (nhận dạng giọng nói), môi trường thay đổi liên tục, hoặc khai phá tri thức từ dữ liệu lớn (Data Mining).
3. Labeled training set là gì? Là tập dữ liệu trong Học có giám sát (Supervised Learning), nơi mỗi mẫu dữ liệu đi kèm với nhãn đúng mong muốn.
4. Hai dạng bài toán phổ biến nhất của Học có giám sát?
- Regression (Hồi quy): Dự đoán giá trị liên tục (số).
- Classification (Phân loại): Dự đoán nhãn rời rạc (lớp).
5. Các tác vụ của Học không giám sát (Unsupervised Learning)? Clustering (Phân cụm), Visualization (Trực quan hóa), Dimensionality Reduction (Giảm chiều dữ liệu), Anomaly Detection (Phát hiện bất thường), Association Rule Learning (Học luật kết hợp).
6. Thuật toán cho robot tự hành? Reinforcement Learning (Học tăng cường). Robot học thông qua cơ chế Thưởng/Phạt (Reward/Penalty) khi tương tác với môi trường.
7. Phân nhóm khách hàng (Customer Segmentation)? Dùng Clustering nếu bạn chưa biết các nhóm là gì. Dùng Classification nếu bạn đã định nghĩa trước các nhóm (ví dụ: “VIP”, “Tiềm năng”, “Rời bỏ”) và có dữ liệu lịch sử.
8. Spam Detection là bài toán gì? Supervised Learning (Classification: Spam hoặc Non-Spam).
9. Online Learning (Học trực tuyến)? Hệ thống học liên tục từ dòng dữ liệu đến (data stream). Thích hợp cho dữ liệu biến đổi theo thời gian hoặc khi dữ liệu quá lớn không thể chứa trong RAM (Out-of-core learning).
10. Out-of-core learning? Kỹ thuật xử lý dữ liệu lớn hơn bộ nhớ chính bằng cách chia nhỏ dữ liệu, huấn luyện từng phần (thường dùng Online Learning algorithms).
11. Instance-based Learning? Hệ thống không xây dựng mô hình tổng quát mà ghi nhớ dữ liệu. Dự đoán dựa trên độ đo tương đồng (similarity measure) với các dữ liệu đã nhớ (ví dụ: k-NN).
12. Model parameter vs. Hyperparameter?
- Model parameter: Được học từ dữ liệu trong quá trình training (ví dụ: weights ).
- Hyperparameter: Được thiết lập trước khi training, điều khiển hành vi của thuật toán (ví dụ: learning rate , số láng giềng , độ mạnh regularization).
13. Model-based Learning? Xây dựng một mô hình toán học đại diện cho dữ liệu. Quá trình học là tối ưu hóa các tham số của mô hình để giảm thiểu hàm mục tiêu (cost function).
14. Thách thức chính của ML? Dữ liệu thiếu (Insufficient quantity), dữ liệu kém chất lượng (Non-representative, Noise), Overfitting (Mô hình quá phức tạp), Underfitting (Mô hình quá đơn giản).
15. Cách xử lý Overfitting?
- Thu thập thêm dữ liệu.
- Giảm độ phức tạp mô hình (giảm bậc đa thức, chọn mô hình đơn giản hơn).
- Regularization (L1, L2).
- Giảm nhiễu (làm sạch dữ liệu).
16. Test Set dùng để làm gì? Đánh giá khách quan hiệu suất của mô hình cuối cùng (Generalization Error). Không bao giờ được huấn luyện trên tập này.
17. Validation Set dùng để làm gì? Dùng để so sánh hiệu suất giữa các mô hình khác nhau và tinh chỉnh Hyperparameters.
18. Train-Dev Set? Dùng khi dữ liệu training và dữ liệu thực tế (production) có phân phối khác nhau. Giúp chẩn đoán xem lỗi đến từ Overfitting hay do Data Mismatch.
19. Tại sao không chỉnh Hyperparameter trên Test Set? Vì điều đó sẽ làm mô hình “học lỏm” tập Test (Data Leakage), dẫn đến kết quả đánh giá quá lạc quan so với thực tế.